
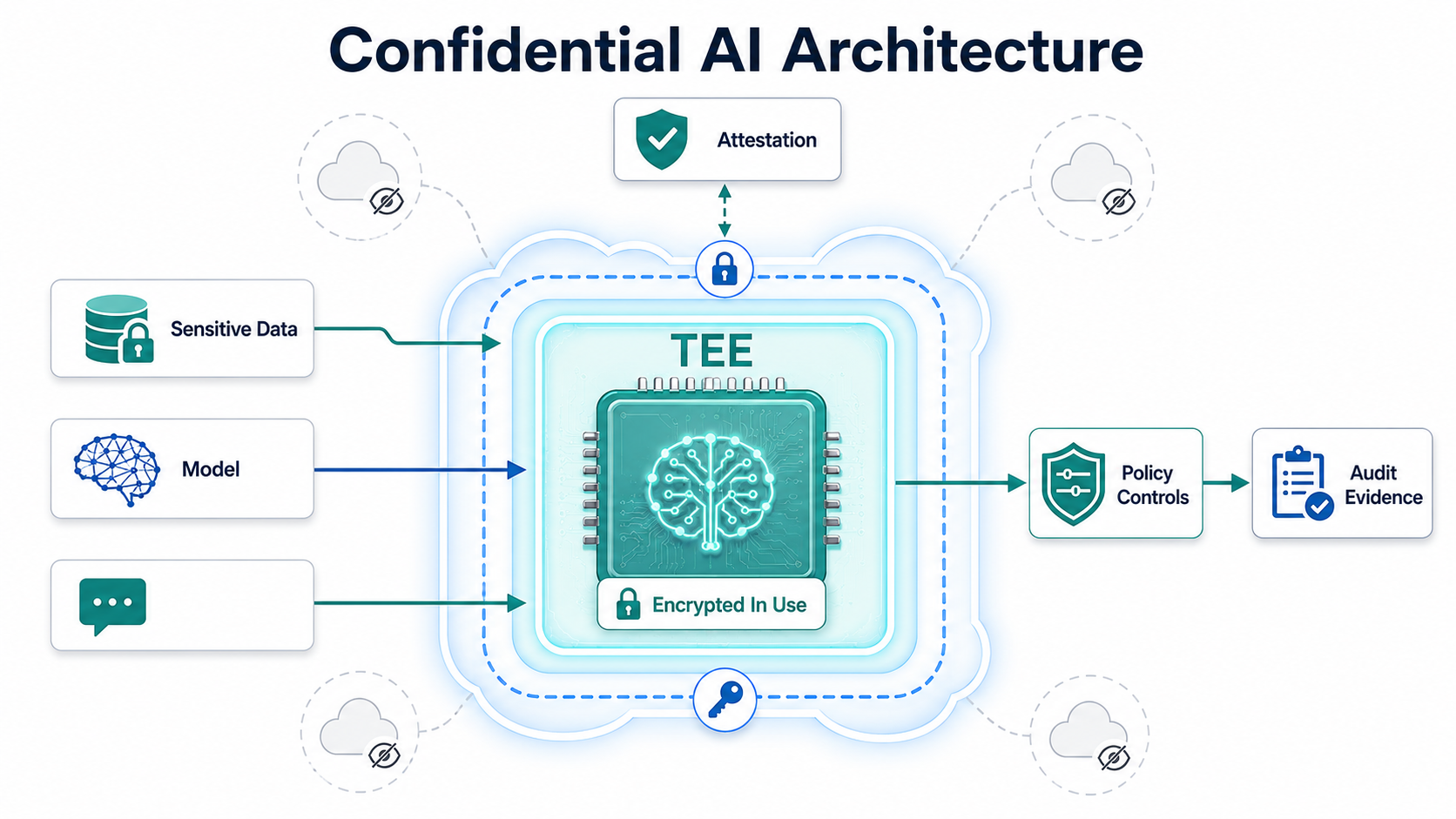
Confidential computing for AI applications is useful when sensitive data, prompts, embeddings, models, or analytics must be processed in the cloud while reducing exposure to infrastructure administrators, neighboring workloads, and some classes of compromised system software. It protects data in use by running selected workloads inside hardware-backed trusted execution environments, then proving the workload state through attestation before secrets or sensitive inputs are released.
It is not a complete AI security program by itself. You still need identity, network controls, secrets management, logging discipline, data governance, model evaluation, prompt controls, and human review. Treat confidential computing as one architecture option for private AI, regulated analytics, multi-party collaboration, and sensitive inference. For broader production planning, pair it with NextPage's generative AI development patterns around workflow design, retrieval, evaluations, and deployment.
Quick Answer: When Should AI Applications Use Confidential Computing?
Use confidential computing when the risk is specifically about exposure during processing. Strong candidates include regulated data analytics, private RAG over sensitive documents, cross-organization model training or scoring, healthcare or financial workflows, high-value proprietary models, and workloads where cloud administrators, host-level compromise, or partner access are part of the threat model.
Do not use it as a shortcut for poor data governance. If the application stores too much data, grants broad access, logs prompts carelessly, or lacks approval controls, a trusted execution environment will not fix the operating model. Confidential computing is strongest when paired with a clear data classification model, a narrow workload boundary, and evidence that the protected boundary is worth the added complexity.
For private knowledge workflows, compare the decision with an enterprise RAG implementation. RAG security often depends as much on source permissions, retrieval filtering, prompt logging, and answer review as it does on the compute boundary.
What Confidential Computing Protects
Traditional cloud encryption protects data at rest and in transit. Confidential computing focuses on data in use: the moment a workload decrypts data into memory so software can process it. Cloud providers now offer confidential VMs, confidential containers or Kubernetes nodes, confidential data processing services, and in some cases confidential GPU-backed workloads for AI inference or training.
The core idea is a trusted execution environment, often shortened to TEE. A TEE isolates application code and data from parts of the surrounding infrastructure. Remote attestation lets a verifier check that the expected workload is running in the expected protected environment before releasing secrets, model assets, customer documents, or sensitive data.
That protection is valuable, but buyers should be precise. Confidential computing can reduce exposure to cloud operator access, privileged host software, neighboring tenants, and some memory-inspection paths. It does not automatically prevent bad application code, malicious users, weak IAM, data leakage through outputs, model inversion, prompt injection, side channels, or unsafe downstream integrations.
Use-Case Fit For Confidential AI
| Use Case | Why Confidential Computing Helps | What Still Needs Design |
|---|---|---|
| Private RAG over regulated documents | Protects retrieval, prompt assembly, and inference data while in use. | Access control, redaction, prompt logging, source permissions, and answer review. |
| Healthcare or financial analytics | Supports sensitive data processing with a narrower infrastructure trust boundary. | Consent, de-identification, audit evidence, data retention, and compliance review. |
| Multi-party data collaboration | Allows parties to contribute data for joint analysis without giving every party raw access. | Contract terms, clean-room rules, output controls, and attestation verification. |
| Proprietary model inference | Reduces exposure of model weights, prompts, and customer inputs during processing. | Model serving controls, output filtering, evaluation, and abuse monitoring. |
| Agent workflows with sensitive tools | Can protect the compute boundary around retrieval, planning, and tool context. | Tool permissions, approval gates, sandboxing, and runtime monitoring. |
If the workload is already low sensitivity, has no external collaboration requirement, or runs entirely inside a trusted private environment, confidential computing may not be worth the added complexity. If the workload is sensitive and cloud migration is blocked by data-in-use concerns, it deserves a serious architecture review.
Architecture Checklist For Confidential AI Workloads
Start with the threat model. Identify who should be unable to see the data during processing: cloud operators, infrastructure admins, other tenants, partner organizations, internal platform teams, or compromised host software. Then define the smallest workload boundary that needs confidential protection.
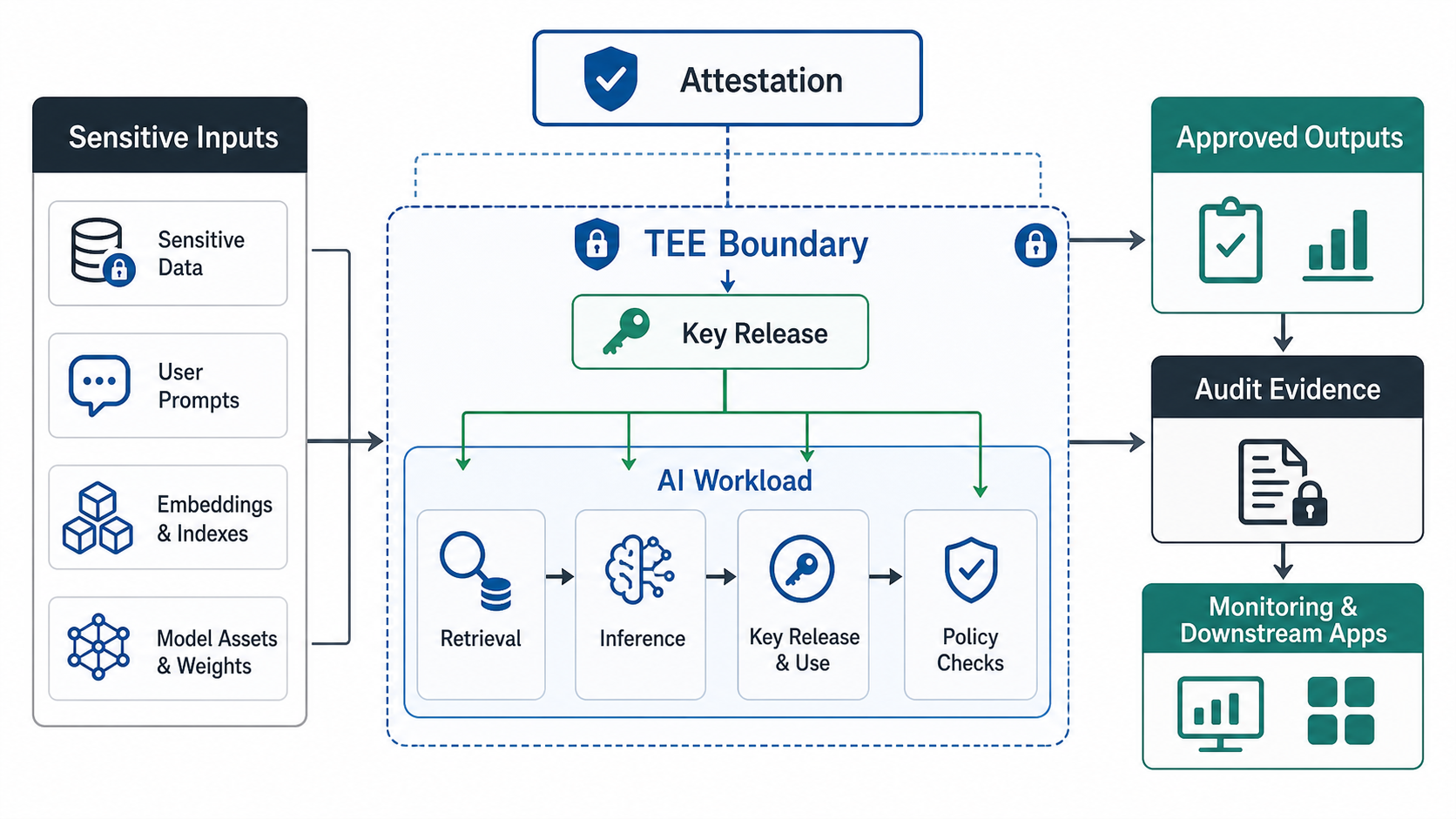
| Architecture Area | Buyer Questions |
|---|---|
| Workload boundary | Which code, model, data, prompts, embeddings, and secrets must run inside the protected environment? |
| Attestation | How will the application verify the TEE state before releasing keys, tokens, or sensitive data? |
| Key management | Who controls keys, when are they released, and how are they revoked? |
| Data flow | Which data enters the TEE, what outputs leave, and where can outputs be stored or logged? |
| Model/runtime | Does the required model, GPU, framework, container, or orchestration layer support confidential deployment? |
| Observability | How will teams monitor health and security without logging sensitive payloads? |
| Fallback | What happens if attestation fails, performance is too low, or a confidential instance type is unavailable? |
For regulated migrations, tie these decisions to broader workload evidence. The regulated application migration checklist covers audit evidence, dependency mapping, cutover, security controls, and validation that also apply to confidential AI deployments.
Attestation, Audit Evidence, And Compliance
Attestation is the proof step that makes confidential computing more than a marketing label. It lets a system verify that the expected workload is running in an acceptable hardware and software state before secrets or sensitive inputs are released. Without attestation, teams may encrypt memory but still lack a reliable way to prove what executed.
For compliance evidence, capture the workload identity, image digest, policy version, TEE type, attestation result, key release decision, data classification, requester identity, and output handling. Keep the evidence useful without creating a new sensitive-data repository. Hashes, event IDs, and redacted summaries are usually safer than raw prompt or document logs.
If the AI application will move from an existing environment to cloud, start with a formal cloud migration assessment. Confidential computing does not remove the need to map dependencies, traffic, operating costs, security controls, and rollback paths.
Cloud And Platform Selection Questions
Platform selection should start with the workload, not the provider brochure. Confirm whether the target architecture needs CPU-only inference, GPU-backed inference, batch analytics, container orchestration, Kubernetes, data clean-room patterns, or enclave-style isolation for a small service. Then test the exact region, runtime, library, accelerator, and observability path you expect to use.
Ask four practical questions before committing. First, can the platform run the model and supporting libraries without unusual rewrites? Second, can attestation integrate with your key-release, secrets, and deployment pipeline? Third, can monitoring prove health and security without leaking prompts, documents, embeddings, or model outputs? Fourth, can the team support incident response when the protected boundary intentionally limits introspection?
For LLM-heavy products, pair platform selection with LLM development decisions around retrieval, context windows, evaluations, latency, caching, output controls, and human review. Confidential compute is only useful if the full application path remains safe.
Performance, Cost, And Operating Tradeoffs
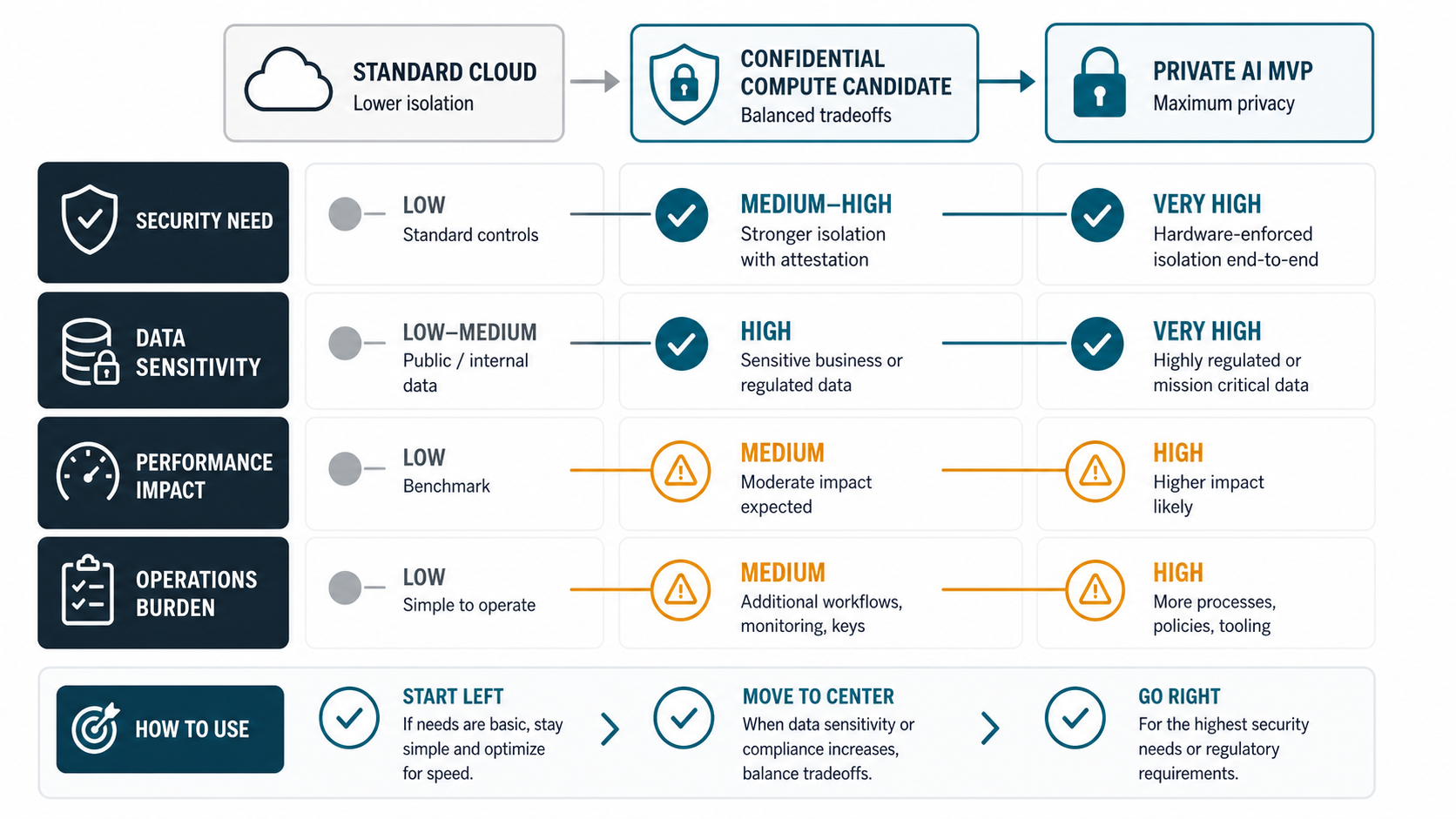
Confidential computing can add cost and constraints. Instance types may be limited. GPU support may vary by provider and region. Some workloads require container, kernel, library, or orchestration changes. Debugging can be harder because the same controls that protect data also limit introspection. Performance depends on CPU, memory, GPU, storage, network, and the workload's access pattern.
Plan a benchmark before committing architecture. Test model latency, throughput, cold start, vector retrieval, batch analytics, memory pressure, key release flow, failure handling, and observability. Compare against non-confidential deployment and alternative privacy patterns. For technology planning beyond confidential compute, use a broader modern custom software tech stack guide approach: AI, cloud, data, security, and operations decisions should be made together.
Alternatives And Complements
Confidential computing is one privacy-enhancing technique. Alternatives or complements include on-prem deployment, private cloud, edge inference, differential privacy, tokenization, data minimization, de-identification, secure multi-party computation, homomorphic encryption, clean rooms, and contractual controls. Each solves a different problem.
For many AI applications, the cheapest privacy improvement is not a new compute primitive. It is reducing data collected, redacting prompts, narrowing retrieval permissions, avoiding raw prompt logs, separating tenants, and requiring human approval for sensitive outputs. Confidential computing should be added when the data-in-use risk remains important after those basics are handled.
Implementation Plan For A Private AI MVP
Step 1: classify the workload. Identify sensitive data classes, model assets, prompt/context data, output risk, users, and regulators or customer commitments.
Step 2: define the trust boundary. Decide which services run inside the confidential boundary and which services remain outside. Keep the protected workload as small as practical.
Step 3: choose platform options. Compare confidential VM, Kubernetes node, data processing, and GPU-backed options across cloud providers. Verify regional availability and framework support.
Step 4: build attestation and key release. Do not release sensitive data or model secrets until the workload presents acceptable evidence.
Step 5: add approval gates and audit logs. Sensitive agent workflows need scoped tools, reviewable actions, and evidence trails. NextPage's secure AI agent development checklist is a useful companion when confidential compute protects the runtime but agents still need policy controls.
Step 6: benchmark and review ROI. Measure latency, throughput, cost, failure modes, and operations burden. Use the AI Agent Readiness Assessment for governance checks and the AI Automation ROI Calculator to keep the business case honest before expanding.
How NextPage Can Help
NextPage helps teams design private AI and regulated cloud architectures with the right amount of security for the workload. That can include data classification, threat modeling, confidential-compute fit analysis, production AI systems, RAG design, key release flows, audit evidence, benchmarks, and rollout planning.
The practical question is not whether confidential computing is impressive. It is whether it closes a real data-in-use gap in your AI workflow at a cost and complexity your team can operate.