
Generic AI APIs are usually the right first step when your NLP workflow can tolerate managed-provider data handling, general language ability, and light integration. Custom NLP becomes worth the extra work when the system must understand domain vocabulary, enforce strict privacy boundaries, cite approved knowledge, run inside a private environment, or connect deeply with business systems. The decision is not API versus custom model in a vacuum. It is a tradeoff between speed, control, evidence, cost, latency, governance, and the business risk of a wrong answer.
For many teams, the best answer is hybrid: start with a managed API, add retrieval-augmented generation for approved knowledge, evaluate against real cases, and only then decide whether fine-tuning, custom classifiers, private deployment, or deterministic workflow logic is needed. NextPage's LLM development work usually starts with this architecture diagnosis before choosing a model or vendor.
Quick Answer: When Is A Generic AI API Enough?
A generic AI API is enough when the input is low-risk, the task is language-heavy but not business-critical, the answer can be checked by a human, and the workflow does not require proprietary domain reasoning. Examples include first-pass summarization, text cleanup, category suggestions, support-draft assistance, internal brainstorming, simple sentiment tagging, and prototypes that prove product value before a deeper build.
Move beyond API-only when any of these are true: the data is sensitive, the vocabulary is specialized, the answer needs source evidence, the model must respect tenant or role permissions, the workflow writes into core systems, latency or unit economics matter at scale, or the business needs measurable accuracy on a narrow task. Those are architecture requirements, not prompt-writing problems.
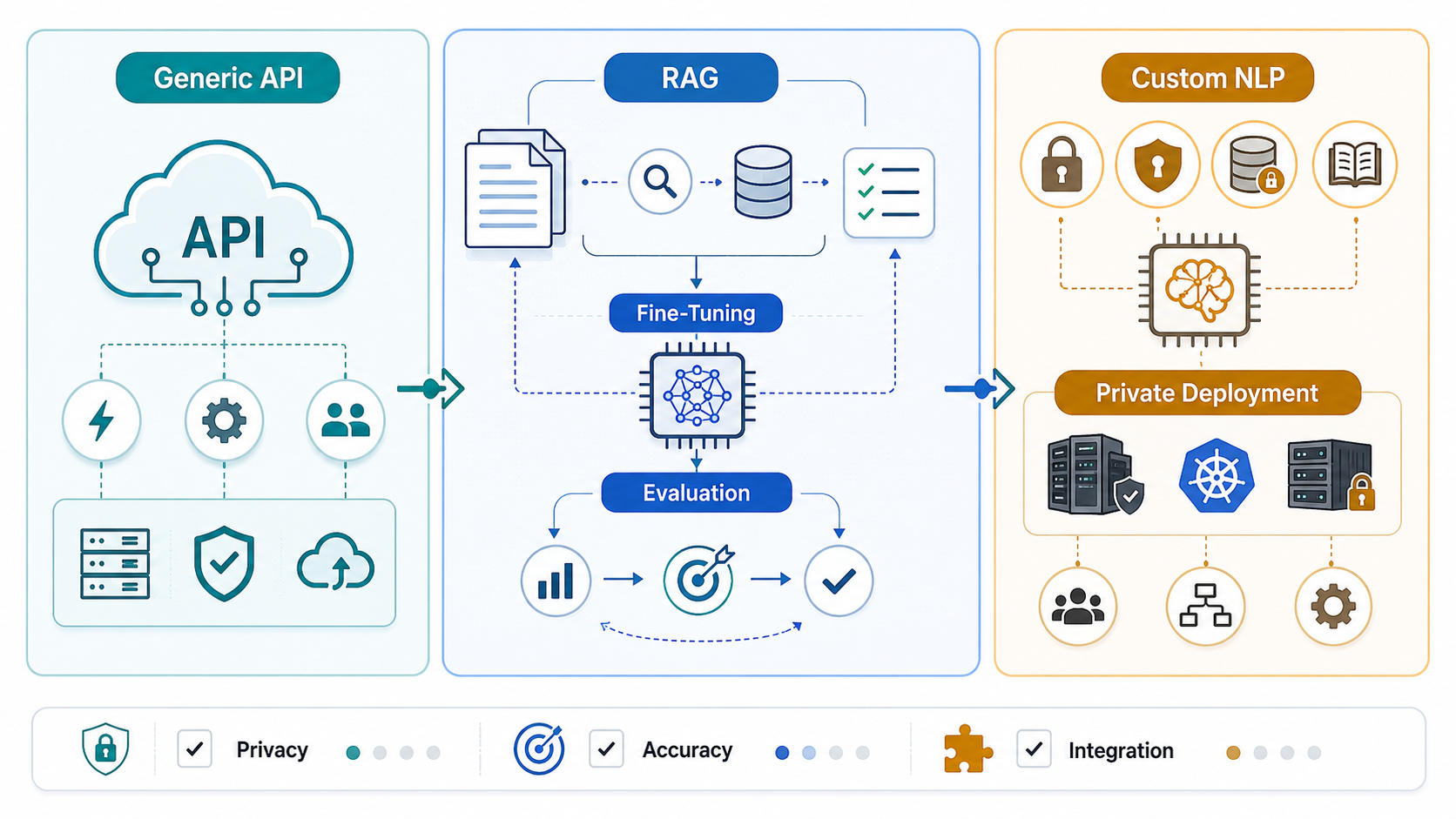
Why The Choice Is Harder Than API Vs Custom
Modern AI APIs are powerful enough that many custom NLP ideas no longer require training a model from scratch. A managed model can classify tickets, extract entities, rewrite content, summarize calls, generate replies, translate text, and answer questions from provided context. That speed is valuable. It lets teams test a workflow in days instead of funding a full machine-learning program upfront.
The catch is that production NLP is rarely just text in and text out. The system may need to retrieve the right policy, enforce customer-specific permissions, avoid sending protected fields to a third party, explain why it made a classification, update a CRM, route an escalation, or pass a regulated audit. Once those constraints appear, the "model" becomes only one part of a larger product architecture.
That is why NextPage treats NLP planning as AI development services, not just model selection. The right architecture may include a generic API, a vector database, rules, evaluation data, workflow automation, human review, monitoring, and private infrastructure.
Comparison Matrix: API, RAG, Fine-Tuning, Custom NLP, Or Private Deployment
| Option | Best For | Main Risk | Use When |
|---|---|---|---|
| Generic AI API | Fast prototypes, drafting, summarization, lightweight extraction, broad language tasks. | Limited control over behavior, retention settings, and domain-specific accuracy. | The task is low-risk, human-reviewed, and does not require private knowledge. |
| RAG workflow | Support bots, internal copilots, policy assistants, document Q&A, sales enablement. | Bad retrieval can ground the answer in the wrong source. | Answers need approved, fresh, private, or cited knowledge. |
| Fine-tuning | Repeated formats, classification, routing, style, narrow behavior, specialized outputs. | Training data quality, privacy, and regression risk. | You have enough examples and prompting/RAG cannot stabilize behavior. |
| Custom NLP model | High-volume extraction, regulated classification, domain entity recognition, deterministic scoring. | Data labeling, maintenance, and model lifecycle overhead. | The task is narrow, measurable, and worth optimizing deeply. |
| Private or open-weight deployment | Strict data boundaries, residency, offline workflows, tenant isolation, sensitive industries. | Infrastructure, security, monitoring, and model-quality burden shifts to your team. | Provider retention, jurisdiction, or access policies do not satisfy requirements. |
| Rules and workflow logic | Permissions, calculations, approvals, irreversible actions, compliance gates. | Overengineering if the decision is genuinely fuzzy. | The system needs deterministic behavior more than language generation. |
Privacy And Data Handling: What Provider Promises Do And Do Not Solve
Provider data policies have improved, but they do not remove the need for architecture decisions. OpenAI's enterprise privacy documentation says business and API Platform data is not used to train models by default, while API inputs and outputs may be retained for up to 30 days for service and abuse monitoring unless eligible zero-data-retention terms apply. Amazon Bedrock documentation says model providers do not have access to Bedrock logs or customer prompts and completions after models are deployed through Bedrock-controlled accounts. Google Cloud documentation says it will not use customer data to train or fine-tune AI/ML models without prior permission or instruction, while some services may still log prompts or responses for abuse monitoring or grounding features.
Those commitments matter. They can make managed APIs acceptable for many business workflows. But privacy is more than "will this provider train on my prompts?" You still need to decide which fields are sent, whether personally identifiable information is masked, how logs are retained, who can view prompt history, whether the model sees tenant-specific data, how output is audited, and what happens when a user asks for information outside their access rights.
If those controls are central to the product, review private generative AI deployment patterns before assuming an API-only architecture is enough. Private deployment is not automatically better, but it can be justified when data residency, isolation, retention, or inspection requirements are stronger than the managed API can support.
Accuracy Depends On Domain Vocabulary And Evidence
Generic AI APIs are strong at broad language tasks, but domain vocabulary can expose gaps quickly. A healthcare operations assistant, insurance claims classifier, legal intake workflow, manufacturing quality assistant, or fintech compliance reviewer may use terms that look ordinary to a general model but carry specific operational meaning. The issue is not whether the model can write fluent text. The issue is whether it consistently maps language to the right business concept.
Use RAG when the answer depends on a source of truth: policy documents, product manuals, SOPs, contracts, knowledge-base articles, call transcripts, onboarding material, or customer-specific records. Use custom classifiers or extraction models when the task has measurable labels and high volume. Consider fine-tuning when the model repeatedly misses the desired style, format, or classification behavior even after strong prompts and retrieval.
Teams should build a small evaluation set before making the custom decision. Include real examples, edge cases, adversarial prompts, ambiguous language, outdated-document traps, role-specific access cases, and the correct fallback answer. Accuracy without evals is just a collection of anecdotes.
Integration Depth Is Often The Real Cost Driver
NLP prototypes often run as a chat window or batch script. Production systems need integrations: CRM, ERP, ticketing, data warehouses, document stores, search indexes, authentication, workflow tools, analytics, and notification systems. A generic API call may be simple, but the surrounding workflow is not.
Ask what the NLP system is allowed to do after it reads or generates text. Can it draft a response only, or can it send one? Can it classify a claim only, or can it approve payment? Can it summarize a contract only, or can it update legal metadata? Can it recommend a support action only, or can it change subscription status? The more the system acts, the more you need permissions, audit logs, validation, rollback, and human review.
This is where generative AI development becomes product engineering. The language model may produce a recommendation, but deterministic software should enforce permissions, calculations, required fields, workflow state, and irreversible actions.
Four Practical Implementation Paths
1. API-Only Prototype
Use this when the goal is to prove whether the workflow creates value. Keep the data low-risk, log examples, and measure whether users accept the output. Do not overbuild retrieval, fine-tuning, or private infrastructure before the product job is clear.
2. API Plus Retrieval
This is the most common production path for knowledge-heavy use cases. Ingest approved content, add metadata, enforce access filters, retrieve relevant passages, and ask the model to answer from that context. The hard part is not the vector database alone. It is content freshness, permission boundaries, chunking, ranking, evals, and review workflows.
3. API Plus Fine-Tuning Or Custom Models
Use this when behavior is repeated and measurable. Examples include classifying support tickets, extracting fields from specific document families, normalizing product descriptions, identifying domain entities, or producing strict structured outputs. Do not fine-tune just to "teach" changing knowledge. Use retrieval for that.
4. Private Or Hybrid NLP Platform
Use this when sensitive data, regulated workflows, tenant isolation, or operating control justify more infrastructure. A hybrid platform may route low-risk tasks to a managed API, sensitive tasks to a private model, and deterministic decisions to application logic. Model routing can improve cost and privacy if the boundaries are explicit.
Cost, Latency, And Operations Tradeoffs
API-only is usually cheapest to start, but not always cheapest to operate. Long prompts, repeated context stuffing, high-volume classification, or slow multi-step chains can create high per-task costs. RAG adds ingestion, vector storage, ranking, and monitoring. Fine-tuning adds data preparation, training, regression testing, and version management. Private deployment adds GPUs or managed inference, security hardening, observability, and incident response.
Measure cost per successful workflow, not cost per token. A cheap API call that produces human rework, compliance review, or customer escalations is not cheap. A custom model that saves inference cost but requires constant data-labeling support may not be worth it. A private deployment that satisfies privacy but underperforms the managed model may fail the user experience.
Latency follows the same logic. A simple API call may be fast. A RAG workflow can be slower if it performs multiple searches and reranking steps. A private model may be faster or slower depending on model size, hardware, quantization, concurrency, and caching. Define the user tolerance before choosing the architecture.
Readiness Checklist Before You Choose Custom NLP
- Data boundary: Which fields, files, and records may be sent to a provider, stored in logs, embedded, or retained?
- Task definition: Is the NLP job generation, classification, extraction, search, routing, translation, summarization, or action recommendation?
- Evaluation set: Do you have realistic examples, expected outputs, scoring rules, and failure cases?
- Source of truth: Does the answer depend on current business documents or static learned behavior?
- Access control: Can retrieval and output respect tenant, role, region, and consent boundaries?
- Human review: Which outputs require approval before reaching customers or changing records?
- Operations: Who owns prompts, retrieval quality, training data, model versions, monitoring, and incident response?
The Enterprise AI Readiness Checklist is a useful pre-step if your team is still mapping data, workflow, security, and governance gaps. If the workflow may become agentic or tool-using, the AI Agent Readiness Assessment helps pressure-test integration access, human review, and governance before the model starts taking action.
Common Mistakes To Avoid
- Choosing custom too early: a generic API prototype may reveal that the workflow, UX, or source data is the real problem.
- Using fine-tuning for fresh knowledge: changing policies, products, and customer records belong in retrieval or tools, not static model weights.
- Ignoring provider retention details: "not used for training by default" is not the same as zero retention, no logging, or no human review in every plan.
- Skipping retrieval evals: if the wrong passage is retrieved, the final answer may look grounded while still being wrong.
- Letting the model enforce permissions: access control should be deterministic application logic, not a prompt request.
- Optimizing for demos: demos reward fluency; production rewards repeatability, auditability, recoverability, and measurable business outcomes.
How NextPage Helps With NLP Architecture Decisions
NextPage helps teams decide what should be API-only, what needs retrieval, what deserves fine-tuning, what should stay deterministic, and what may require private deployment. We start with workflow mapping, data sensitivity, evaluation cases, integration needs, and operating constraints. Then we design the smallest architecture that can meet the business requirement without hiding risk inside a prompt.
If you are comparing generic AI APIs with custom NLP, start with an architecture review. We can help map your use case, identify privacy and integration constraints, build an evaluation set, and choose between API, RAG, fine-tuning, custom models, private deployment, or a hybrid path.