
Quick Answer: What Should An MLOps Implementation Include?
An MLOps implementation should include more than a model endpoint. A production-ready setup needs data validation, model versioning, reproducible pipelines, CI/CD gates, deployment controls, monitoring signals, retraining triggers, governance evidence, cost ownership, and a rollback path when a model or pipeline starts causing damage.
Use this checklist before you scale a machine learning pilot. The goal is to decide whether the model can be operated safely by a real team, not whether the notebook looked promising in a demo. If you need help translating a pilot into production architecture, NextPage's AI development services team can help design the product, data, pipeline, and monitoring plan. For infrastructure dependencies, review the cloud migration services path before committing to platform choices.
Why MLOps Is Different From Model Development
Model development proves that a prediction, recommendation, ranking, or automation may be useful. MLOps proves that the model can be delivered, observed, improved, and retired without turning every release into a manual rescue effort. That difference matters when business data changes, user behavior shifts, upstream systems break, or a model starts producing outputs that no longer match operational reality.
The SparxIT reference page positions MLOps as a way to optimize deployment, performance, automation, and cloud/DevOps alignment. That is a useful service frame, but buyers still need a concrete implementation checklist. A team should know who owns the data, which model artifact is live, what tests block deployment, what signals trigger alerts, who approves retraining, and how rollback works before production traffic depends on the model.
Google Cloud's MLOps architecture guidance makes the same operational point: production ML is not just deploying a prediction API; mature systems deploy pipelines that can automate retraining and deployment of new models. For software teams already improving release operations, the MLOps plan should connect to broader DevOps consulting for SaaS teams practices such as CI/CD, observability, infrastructure automation, and rollback.
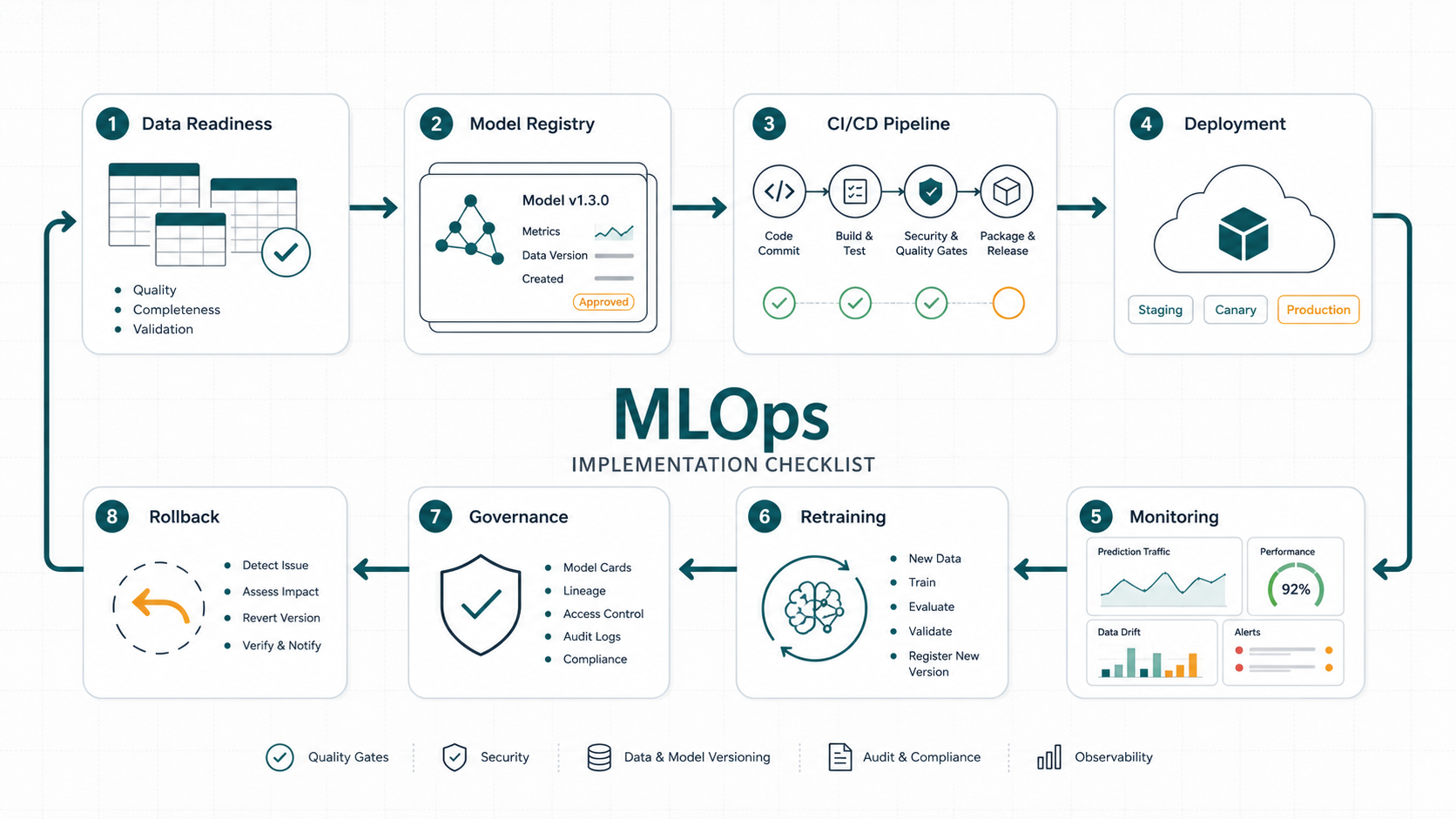
MLOps Readiness Map

Use the map below as a working scorecard. Each row should have an owner, evidence, and a launch decision.
| Checklist area | Required evidence | Common failure if skipped |
|---|---|---|
| Data readiness | Data contracts, quality checks, lineage, privacy boundaries, and reference datasets | The model trains or predicts on data no one trusts |
| Model registry | Versioned artifacts, metrics, approval status, owner, intended use, and rollback candidate | Teams cannot explain which model is live or why |
| Pipeline automation | Repeatable training, validation, packaging, environment, and deployment pipeline | Releases depend on notebook steps and manual memory |
| Deployment gates | Automated tests, security checks, model acceptance thresholds, and staged rollout controls | Bad model versions reach users too quickly |
| Monitoring | Production inference capture, data drift, prediction drift, quality, performance, and alert thresholds | Model degradation is discovered by customers or operators |
| Retraining | Trigger rules, evaluation data, approval workflow, release notes, and rollback plan | Fresh models are shipped without operational review |
| Governance | Risk classification, human review, audit logs, access control, and change history | No one can defend model behavior after an incident |
| Cost controls | Compute budgets, storage budgets, training cadence, endpoint scaling, and alerting | The platform becomes expensive before value is proven |
Step 1: Define The Production Use Case And Owner
MLOps starts with an operating decision, not a tool decision. Define the prediction or automation, the user who relies on it, the business metric it affects, the fallback if it fails, and the person who can approve changes. A fraud score, lead score, churn forecast, demand forecast, recommendation engine, routing model, and document classifier all need different thresholds, review flows, and monitoring signals.
Answer these questions first:
- What decision or workflow will the model influence?
- Who owns the business outcome, data quality, model quality, platform reliability, and support process?
- What is the minimum acceptable model performance before production launch?
- Which outputs require human review, and which can be automated?
- What is the fallback path when the model is unavailable, wrong, stale, or too expensive?
For teams still deciding whether an AI use case is ready, the AI Agent Readiness Assessment is useful even for non-agent ML projects because it scores workflow clarity, data readiness, integration access, and governance gaps.
Step 2: Build Data Readiness Before Training Automation
Production models inherit the quality of production data. Before automating training, define source systems, data contracts, ownership, retention rules, privacy constraints, missing-value handling, schema expectations, label quality, and ground-truth collection. This is where many ML projects fail: the model is treated as the product, while data quality remains an informal agreement.
Create launch gates for data readiness:
- Document source systems and business definitions for each important feature.
- Version training, validation, and test datasets or make them reproducible from versioned inputs.
- Run automated checks for nulls, out-of-range values, type mismatches, duplicate records, and unexpected category shifts.
- Define which data can be used for training, inference, monitoring, and debugging.
- Capture feature lineage so teams can investigate performance changes after upstream system updates.
Azure Machine Learning's model monitoring documentation describes data quality signals such as null value rate, data type error rate, and out-of-bounds rate. Those are not the only checks a team needs, but they show why data readiness must be measurable before production.
Step 3: Create A Model Registry And Release Contract
A model registry is the shared record for model artifacts and release decisions. It should tell the team which model version is approved, where it came from, which dataset and code produced it, what metrics it achieved, who approved it, what risk class it carries, and which previous version can be restored.
At minimum, record:
- Model version, code version, dataset version, training environment, and dependency versions.
- Offline metrics, validation slices, fairness or bias checks where relevant, and known limitations.
- Intended use, excluded use cases, input assumptions, and human review requirements.
- Approval status, approver, approval date, release notes, and rollback candidate.
- Endpoint, batch job, or embedded application where the model is deployed.
This registry does not have to be complicated at the beginning. It has to be reliable enough that product, data science, engineering, and operations can answer the same release questions.
Step 4: Automate CI/CD For Models And Pipelines
MLOps CI/CD should test code, data assumptions, pipeline components, model quality, packaging, security, and deployment configuration. Google Cloud's MLOps guidance highlights automated data validation, model validation, pipeline triggers, metadata management, and continuous delivery of models trained on new data. The practical lesson is simple: do not automate deployment until the validation gates are explicit.
A useful MLOps pipeline includes:
- Source control for pipeline code, feature logic, infrastructure configuration, and evaluation scripts.
- Automated tests for data transforms, feature creation, inference contracts, and API behavior.
- Model acceptance thresholds for global metrics and important business segments.
- Security and dependency checks for container images, secrets, and service permissions.
- Staging deployment, shadow testing, canary rollout, or batch validation before full release.
For cloud-hosted systems, MLOps usually depends on platform architecture. That is why cloud readiness, network access, storage design, identity, and cost controls should be reviewed alongside the ML pipeline, not after it.
Step 5: Monitor Drift, Quality, Performance, And Business Impact
Monitoring is where MLOps becomes operational. Azure describes production model monitoring as comparing production inference data against reference data and using metrics and thresholds to alert on anomalies. AWS notes that model monitoring can detect deviations in model quality, bias, and feature importance. The exact tool is less important than the signal design.
Track four categories of signals:
- Data signals: schema changes, missing values, out-of-range values, distribution shift, and feature availability.
- Prediction signals: output distribution, confidence patterns, class balance, rejection rates, and unusual clusters.
- Performance signals: accuracy, precision, recall, calibration, latency, throughput, error rates, and user feedback where ground truth is delayed.
- Business signals: conversion, fraud loss, forecast error, support tickets, operator overrides, customer complaints, and cost per decision.
Monitoring should lead to action. Define who receives alerts, what threshold creates investigation, what threshold pauses automation, and what threshold triggers rollback or retraining.
Step 6: Govern Risk, Human Review, And Audit Evidence
NIST describes the AI Risk Management Framework as voluntary guidance for incorporating trustworthiness considerations into the design, development, use, and evaluation of AI systems. For MLOps teams, that means governance should be visible in the delivery workflow: risk classification, access control, human review, approval logs, monitoring evidence, incident notes, and change history.
Governance questions to answer before launch:
- What harm could occur if this model is wrong, biased, delayed, unavailable, or misused?
- Which user groups, data segments, or operational states need separate evaluation?
- Who can approve a new model version, change thresholds, bypass checks, or disable automation?
- What logs are retained for prompts, features, predictions, explanations, user actions, and approvals?
- How will the team investigate and report incidents?
For adjacent governance patterns, see NextPage's enterprise AI agent governance guide and EU AI Act readiness checklist. Even when a model is not an agent and is not governed by a specific AI law, the evidence discipline is still useful.
Step 7: Plan Retraining, Cost Controls, And Rollback
Retraining should not be a reflex. New data can improve a model, but it can also introduce bias, leakage, schema errors, or cost spikes. Define retraining triggers, evaluation data, approval steps, release notes, and rollback before the first production version goes live.
Build a clear operating plan:
- Retrain because a defined signal changed, not because a calendar date arrived.
- Separate investigation, training, evaluation, approval, deployment, and monitoring windows.
- Set budgets for training jobs, feature storage, online endpoints, monitoring jobs, and human review.
- Keep a known-good model version and configuration ready for rollback.
- Practice rollback before a real incident.
If the model is part of a broader AI product rollout, connect this plan to an AI implementation roadmap so product, engineering, data, security, and operations teams agree on phases and responsibilities.
Red Flags In An MLOps Proposal
- Tool-first scope: the proposal starts with platform names but does not define owners, data contracts, monitoring signals, or rollback.
- No production inference capture: the team cannot explain how model inputs, outputs, and outcomes will be collected for monitoring.
- Notebook-dependent release: model training or evaluation depends on manual notebook execution instead of reproducible pipelines.
- Weak approval model: no one can say who approves model promotion, threshold changes, retraining, or rollback.
- No cost guardrails: training, storage, endpoint, and monitoring costs are not budgeted or alerted.
- Governance after launch: audit logs, model cards, access controls, and risk review are treated as documentation work after deployment.
How NextPage Helps With MLOps Implementation
NextPage helps teams move machine learning from promising prototypes to maintainable production systems. That can include model deployment architecture, data readiness review, CI/CD pipeline planning, monitoring design, governance evidence, cloud readiness, integration work, and support ownership.
If your team has a working model but not a production operating model, bring the current notebook or pipeline, data sources, target workflow, infrastructure constraints, and launch timeline to a planning session. We will help identify the gaps that matter before you scale.
Review model deployment and monitoring readiness with NextPage.