
Quick Answer: AI Development Lifecycle
The AI development lifecycle is the governed path for taking an AI use case from idea to production and then keeping it reliable after launch. It covers use-case selection, data readiness, prototype design, model or LLM integration, evaluation, security review, release, monitoring, feedback, and continuous improvement.
The important difference from a traditional software lifecycle is that AI quality depends on data, prompts, retrieval, model behavior, human review, cost, drift, and production feedback. Shipping the first version is not the end of delivery. It is the start of an operating loop.
For teams planning an AI product, copilot, RAG assistant, prediction workflow, or agentic automation, the right lifecycle prevents the common trap: a promising proof of concept that cannot survive production. NextPage's AI development services are built around this practical lifecycle: define the workflow, validate the data, evaluate outputs, add controls, release safely, and monitor what happens in real use.
Why SDLC Is Not Enough For AI
Traditional software delivery assumes the code behaves deterministically. Requirements can change, defects can appear, and systems can fail, but the same input usually produces the same output. AI systems are different. A model may return different answers for similar prompts, retrieval quality can shift as content changes, prediction quality can drift as real-world behavior changes, and a model update from a provider can affect output style or accuracy.
The source article frames this as the gap between SDLC and ADLC: AI is probabilistic, data-dependent, and continuously operational. That framing is useful, but buyers need a more concrete question: what evidence must exist before an AI feature is allowed into production?
The answer is not "more AI." The answer is a lifecycle with explicit gates. Each gate should prove that the team knows the business goal, data limits, evaluation method, human review path, security posture, operating cost, rollback plan, and monitoring signals.
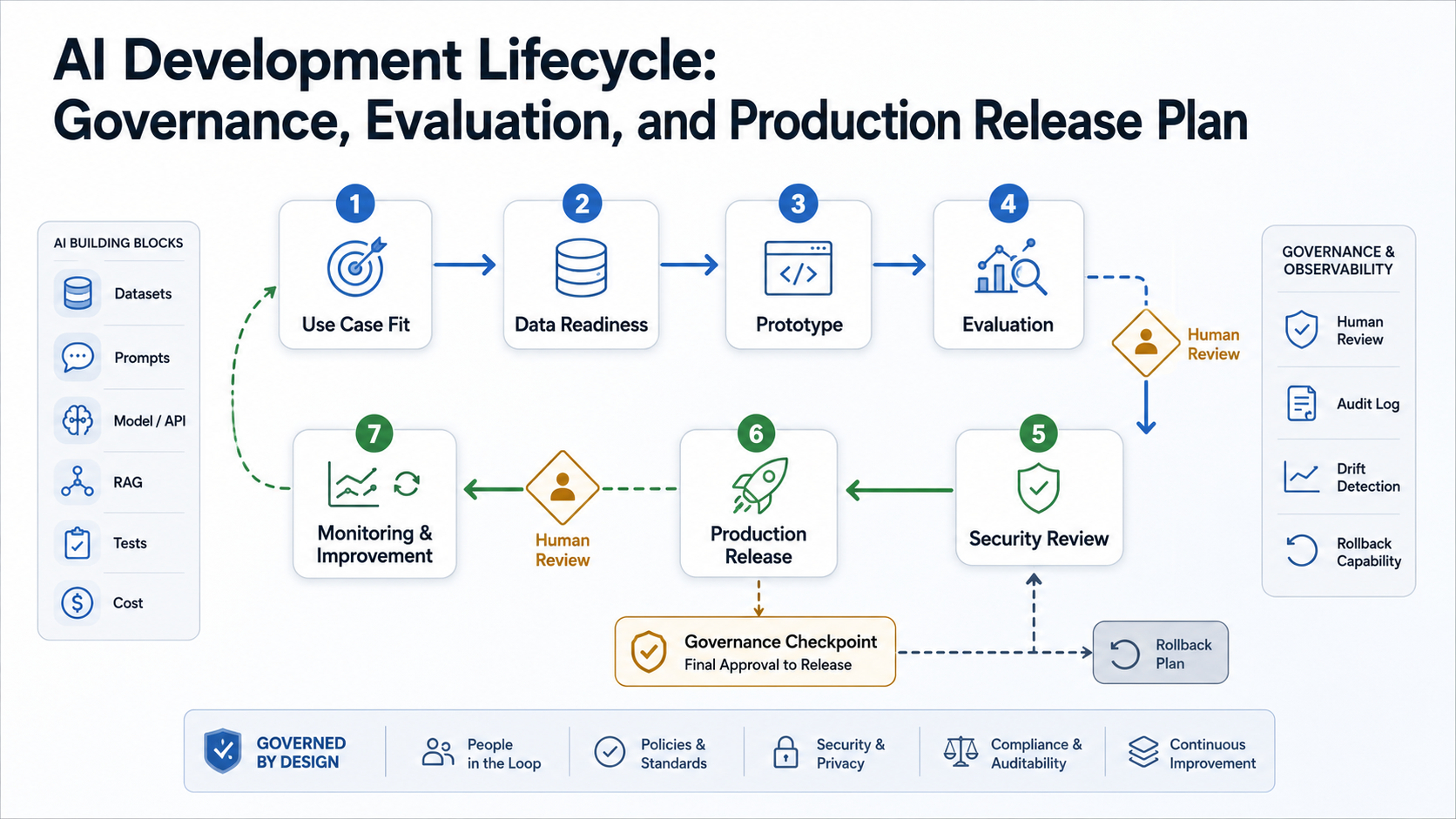
AI Development Lifecycle Stages
A practical AI lifecycle has eight stages. Teams can run some stages in parallel, but skipping one usually creates production risk later.
| Stage | Key question | Required evidence |
|---|---|---|
| Use-case fit | Should this workflow use AI? | Business problem, users, success metric, risk level, non-AI baseline |
| Data readiness | Is the input trustworthy and accessible? | Data sources, permissions, lineage, quality, freshness, privacy constraints |
| Architecture choice | What pattern fits the use case? | API model, RAG, fine-tuning, classical ML, agent, workflow rules, or hybrid design |
| Prototype | Can the workflow produce useful output? | Thin demo with realistic inputs, edge cases, and reviewer feedback |
| Evaluation | How will quality be measured? | Golden datasets, acceptance criteria, failure taxonomy, regression tests |
| Security review | Can the system protect users and data? | Access controls, prompt injection checks, sensitive-data handling, audit logging |
| Production release | Can the team operate it safely? | Monitoring, cost limits, fallback, rollback, support process, owner |
| Improvement loop | How will it learn from production? | Feedback capture, drift checks, retraining or prompt updates, release notes |
If the use case is language-heavy, such as a RAG assistant or AI copilot, review the options in NextPage's LLM development services. If the work is predictive, ranking, or classification-heavy, NextPage's machine learning development services page is the better planning route.
Data Readiness Is A Lifecycle Gate
Most AI delivery problems are not model-selection problems. They are data, workflow, ownership, and evaluation problems. Before the team commits to production scope, it should be able to answer five data-readiness questions:
- Access: Can the application reach the required data through approved APIs, databases, documents, events, or integrations?
- Permission: Is the data allowed to be used for this AI workflow, with the right user, tenant, consent, retention, and regional controls?
- Quality: Is the data complete, current, deduplicated, labeled, and representative enough for the intended decision?
- Context: Does the system know which source, timestamp, customer, policy, product, or workflow state the answer depends on?
- Feedback: Can user corrections, reviewer decisions, and production failures be captured for future improvement?
For RAG systems, data readiness also includes chunking strategy, metadata, permissions-aware retrieval, source citation, and stale-content handling. For machine learning, it includes training and validation splits, leakage checks, feature definitions, and drift baselines. For AI agents, it includes tool permissions, action logs, and safe rollback.
A simple data-readiness score prevents premature build decisions. Rate each source from 1 to 5 for access, permission, quality, freshness, and evaluation usefulness. Any source scoring below 3 should be treated as a risk, not as a production dependency. This turns lifecycle planning into an engineering conversation instead of a model demo.
Governance And Ownership Model
AI governance is not just a policy document. It is the operating model that decides who can approve data, prompts, models, tests, deployment, monitoring, and exceptions. Without named owners, AI quality becomes everyone's concern and nobody's responsibility.
| Owner | Lifecycle responsibility | Decision rights |
|---|---|---|
| Business owner | Defines value, acceptable risk, and success metrics | Approves use-case fit and launch readiness |
| Product owner | Owns workflow, user experience, feedback, and roadmap | Prioritizes scope and tradeoffs |
| Data owner | Validates source quality, permissions, retention, and lineage | Approves data use and refresh rules |
| Engineering owner | Owns architecture, integration, deployment, performance, and rollback | Approves technical release readiness |
| Security/compliance owner | Reviews access, logging, privacy, abuse cases, and audit needs | Approves control evidence |
| Human reviewer group | Accepts, edits, rejects, and labels AI outputs | Shapes evaluation data and escalation rules |
Teams considering autonomous or tool-using agents should start with the AI Agent Readiness Assessment. Agentic workflows need extra clarity around permissions, action boundaries, audit logs, and human approval.
Evaluation Gates Before Release
AI evaluation should be designed before the prototype becomes a production feature. A good evaluation gate compares model behavior with business risk. For example, a product recommendation widget can tolerate some imperfect suggestions. A loan-processing, healthcare, or security workflow cannot treat false positives and false negatives casually.
Use at least five gates before release:
- Functional quality: Does the output solve the intended job for realistic inputs?
- Grounding quality: For RAG or knowledge assistants, are answers supported by the right sources?
- Safety and abuse resistance: Can prompt injection, unsafe requests, data leakage, or policy bypasses be detected?
- Human review fit: Can reviewers accept, edit, reject, escalate, and explain outputs quickly?
- Operational reliability: Are latency, cost, rate limits, fallback, observability, and rollback understood?
Generative AI projects often fail when teams evaluate demos instead of workflows. NextPage's generative AI development work treats prompts, retrieval, evaluations, permissions, and business integration as one system rather than separate experiments.
Production Release Plan
An AI production release should look more like a controlled rollout than a feature toggle. The release plan should define users, risk tier, allowed actions, monitoring, and rollback triggers before the launch date.
| Release item | What to define | Example evidence |
|---|---|---|
| Scope | Which users, workflows, and inputs are included? | Launch cohort, supported tasks, excluded cases |
| Quality threshold | What result is good enough for release? | Eval pass rate, reviewer acceptance rate, known limitations |
| Human review | When does a person approve or override? | Escalation rules, reviewer UI, audit record |
| Monitoring | What production signals are watched? | Latency, cost, errors, acceptance, drift, complaint rate |
| Rollback | What shuts the feature down or downgrades behavior? | Kill switch, fallback workflow, owner notification |
| Change control | How are prompts, models, data, and policies updated? | Versioning, approval, test run, release notes |
This release evidence is also useful for budget and roadmap planning. If the lifecycle reveals major integration or governance work, estimate it before a full build using the Custom Software Cost Estimator.
Monitoring And Improvement Loop
AI systems need monitoring that connects model quality to business outcomes. Logs alone are not enough. The team needs to know whether outputs are accepted, edited, ignored, escalated, or causing support friction.
Track these signals:
- Input volume by workflow, user role, and source system.
- Output acceptance, edit, rejection, and escalation rates.
- Grounding failures, missing-source failures, hallucination reports, and policy violations.
- Latency, token or inference cost, vendor errors, and fallback usage.
- Drift in data distribution, retrieval coverage, model quality, and user behavior.
- Business metrics such as resolution time, conversion, throughput, error reduction, or analyst productivity.
For ML-heavy systems, NextPage's MLOps implementation checklist is a useful companion because it covers deployment, monitoring, governance, and model improvement practices in more detail.
Cost, Vendor, And Operations Controls
AI lifecycle planning also needs commercial controls. A prototype can look affordable because it runs on a small set of test prompts. Production traffic changes the economics. Retrieval calls, model tokens, embedding jobs, image or document processing, vector storage, observability, review time, and vendor failover can all become operating costs.
| Control area | Question to answer | Production artifact |
|---|---|---|
| Cost model | What is the expected cost per user, task, document, or transaction? | Unit-cost estimate with traffic assumptions |
| Budget guardrails | What happens when usage spikes or a workflow loops? | Rate limits, quotas, alerts, and fallback behavior |
| Vendor dependency | What fails if the model, API, or vector store is unavailable? | Fallback plan, retry policy, cached response rules |
| Model updates | How are provider changes or model migrations tested? | Regression suite and release approval |
| Support workflow | Who handles bad outputs, user complaints, and audit requests? | Support playbook and escalation owner |
| Change history | Can the team explain which version produced an output? | Prompt, model, data, policy, and release version log |
These controls are not bureaucracy. They are what let a team scale a useful AI feature without losing control of reliability, customer trust, or margin. They also help executives compare build options: a small workflow assistant, an internal copilot, a production RAG assistant, a custom ML model, or a multi-step agent do not carry the same cost and operational burden.
The lifecycle should therefore include a business review before production. The review should confirm that expected usage, cost per task, quality threshold, risk tier, owner availability, and support obligations still justify the release.
Common Failure Modes
The AI lifecycle exists because AI failures often appear after the demo works. Watch for these patterns:
- Use-case inflation: a small assistant becomes a platform before the first workflow is proven.
- Data optimism: the team assumes source data is complete, current, permissioned, and clean before testing it.
- Eval theater: the demo has test prompts, but no golden dataset, edge cases, or regression suite.
- No human review design: reviewers are expected to catch mistakes, but the product gives them no evidence, context, or escalation path.
- Unowned cost: token, retrieval, inference, storage, and monitoring costs are not assigned to a product owner.
- Silent drift: production behavior changes but the team has no baseline to detect it.
- Model update surprises: provider or prompt changes affect output style without release notes or rollback.
Implementation Roadmap
A realistic first lifecycle rollout can be completed in four focused phases.
| Phase | Work | Output |
|---|---|---|
| 1. Discovery | Use-case fit, data audit, risk tier, success metric, owner map | AI opportunity brief |
| 2. Prototype | Architecture option, sample data, prompt/retrieval/model experiment, reviewer feedback | Thin AI workflow |
| 3. Evaluation | Golden set, failure taxonomy, security tests, cost benchmark, human review design | Release evidence pack |
| 4. Production | Deployment, monitoring, fallback, rollback, feedback loop, iteration cadence | Operated AI feature |
The best lifecycle is not the heaviest one. It is the lightest governance structure that makes the system trustworthy for its risk level. A customer-support summarizer, a product-recommendation engine, a fraud workflow, and an autonomous agent do not need the same review burden. They do need explicit owners, evidence, and monitoring.
Next Steps
If your team is planning an AI feature, do not start by choosing a model. Start by defining the workflow, data, risk tier, evaluation method, and release owner. Then decide whether you need a simple AI API integration, a RAG system, a custom ML model, a fine-tuned LLM, or an agentic workflow.
NextPage can help turn an AI idea into a production plan through AI development services, LLM development, generative AI development, and machine learning development services. The right engagement should leave you with more than a demo: it should produce a release plan your product, engineering, data, and business teams can operate.