
Quick Answer: What Is A Machine Learning Integration Roadmap?
A machine learning integration roadmap is a phased plan for adding predictive, recommendation, classification, computer vision, or NLP capabilities to software that already runs your business. It connects the business use case, available data, model approach, API/service design, product UX, security controls, testing plan, MLOps, monitoring, and rollout sequence into one implementation path.
The important word is integration. A model in a notebook does not change a workflow. A model embedded in a CRM, ERP, dashboard, mobile app, internal tool, or customer portal can improve decisions when users trust the output, the surrounding software captures feedback, and the operating team can monitor quality after launch.
For most teams, the safest sequence is: choose one valuable workflow, audit the data, build a baseline model, wrap it in a secure service, embed predictions into the existing user journey, add human review where the risk is meaningful, monitor model and data behavior, and expand only after the pilot proves measurable value. NextPage's AI development services and machine learning development services follow this production-first path so ML work does not stay trapped in experimentation.
For 2026 planning, the roadmap should also account for model monitoring, governance evidence, and continuous training or retraining triggers before the pilot expands. Google Cloud frames mature MLOps around CI, CD, and continuous training for ML systems, while Azure model monitoring emphasizes production performance from both data-science and operational perspectives. That means a useful integration roadmap must define not only how the model is built, but how it is observed, paused, improved, and defended after launch.
When ML Integration Makes Sense For An Existing App
Machine learning is worth integrating when a repeated decision depends on patterns that are hard to capture with static rules. Good candidates include churn risk, lead scoring, anomaly detection, demand forecasting, product recommendations, document classification, image review, ticket routing, support triage, fraud signals, and operational prioritization.
Weak candidates usually have unclear ownership, tiny data volume, inconsistent labels, no measurable decision point, or a workflow where users cannot act on the prediction. In those cases, simpler reporting, workflow automation, better forms, rule-based scoring, or process redesign may produce faster returns.
Use the first discovery workshop to define the work, not the algorithm. Name the user, decision, moment of use, input data, acceptable latency, business metric, risk level, and fallback behavior. If the feature must live inside an existing product, include product and engineering owners from the start. A team building with web app development discipline will usually ask these questions before it talks about model families.
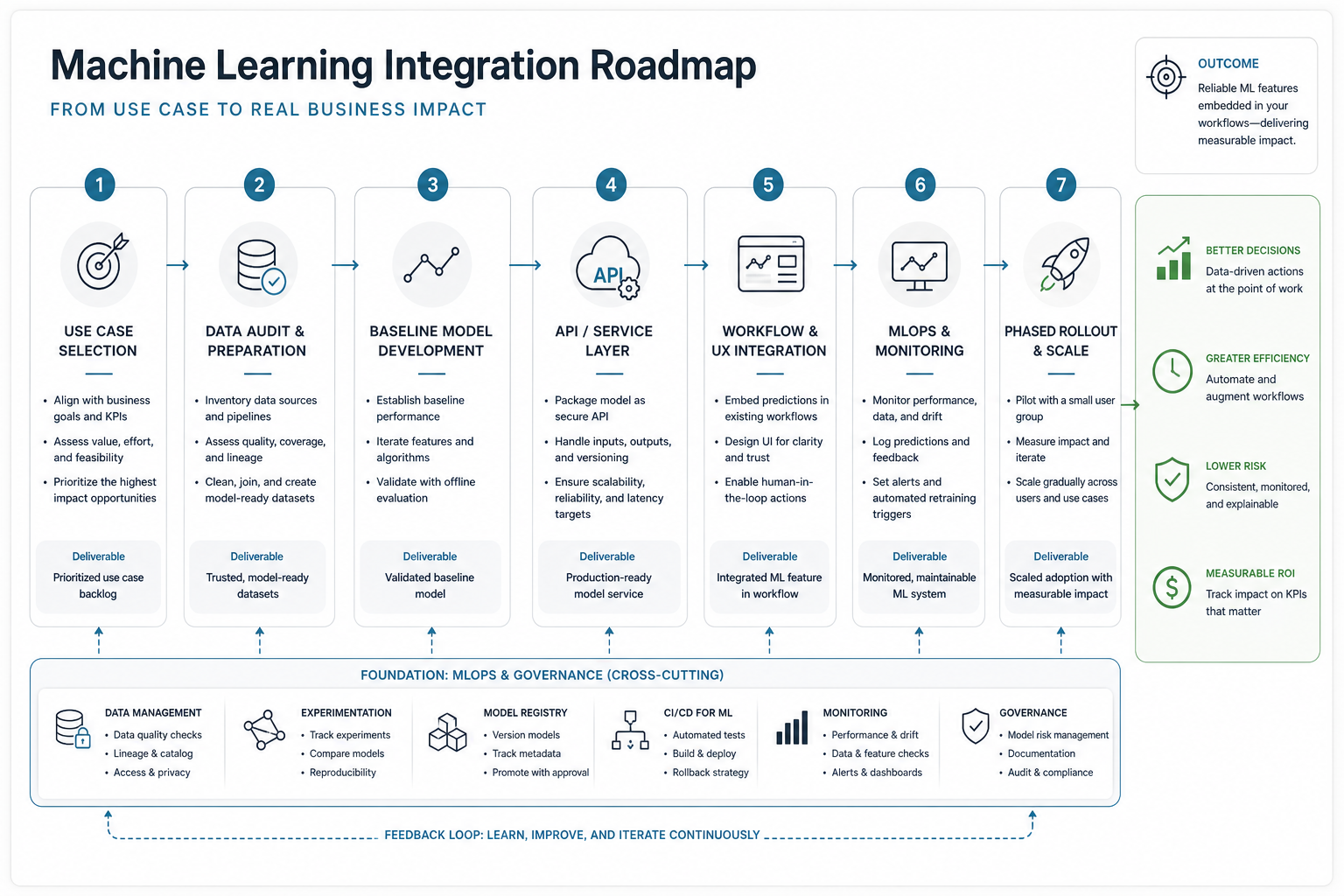
The ML Integration Roadmap At A Glance
The roadmap below keeps the model tied to software delivery. You can compress or expand the phases, but skipping one usually creates rework later.
| Phase | Main Question | Key Deliverable | Decision Gate |
|---|---|---|---|
| 1. Use-case selection | Which workflow is valuable and measurable? | Prioritized ML use-case brief | Expected value and operational owner are clear |
| 2. Data audit | Can available data support the decision? | Source inventory, quality review, label plan | Data access, ownership, and quality risks are known |
| 3. Baseline model | Does ML beat current rules or manual review? | Offline baseline with evaluation results | Improvement justifies a pilot |
| 4. Service design | How will the app request and use predictions? | Model API, data contracts, security pattern | Latency, reliability, versioning, and access controls fit production needs |
| 5. Workflow UX | How will users see, trust, and act on output? | Updated screens, alerts, review queues, explanations | Users can accept, override, or escalate predictions |
| 6. MLOps | How will the system be monitored and improved? | Deployment, monitoring, retraining, rollback plan | Ownership and incident response are assigned |
| 7. Rollout | How will the team scale without losing control? | Pilot plan, KPI dashboard, expansion backlog | Measured outcomes support broader adoption |
ML Integration Readiness Scorecard
Before moving from roadmap to build, score the workflow across five readiness dimensions. A high score does not mean the project is easy; it means the team can make decisions with fewer unknowns and fewer production surprises.
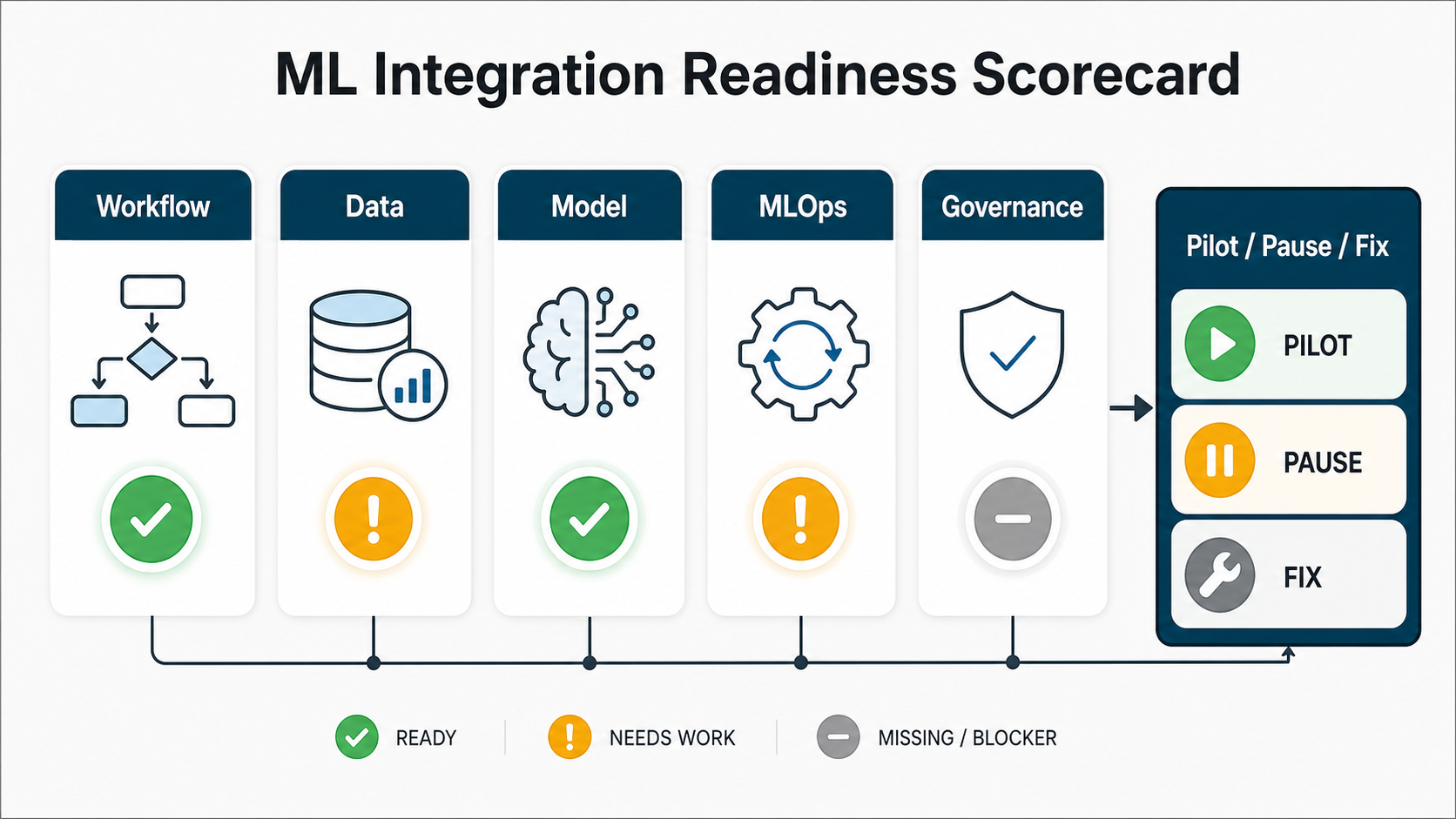
| Readiness Dimension | Green Signal | Risk To Resolve Before Build |
|---|---|---|
| Workflow clarity | The user, decision point, success metric, and fallback path are named. | The team wants ML in general but cannot identify the operational decision it will improve. |
| Data access | Historical inputs, outcome labels, and real-time prediction inputs are available with owners. | Data exists across systems but nobody can confirm quality, permissions, or label meaning. |
| Integration surface | The app, API, queue, dashboard, or CRM screen that will consume predictions is known. | The model can be trained, but there is no agreed product workflow for using the output. |
| Human review | Users can accept, override, correct, or escalate predictions based on risk level. | The plan jumps from prediction to automation without a review path for uncertain cases. |
| Operations ownership | Monitoring, rollback, retraining, incident response, and KPI review have named owners. | The pilot would launch without someone accountable for drift, quality drops, or support issues. |
If several rows are still yellow or red, use a readiness tool such as the AI Agent Readiness Assessment as a planning proxy. Even when the first release is predictive ML rather than an agent, the same questions around workflow clarity, data readiness, integration access, governance, and human review expose gaps early.
Start With Use-Case Selection, Not A Model
The best first ML integration is usually narrow. It improves a repeated workflow, has an obvious owner, touches data you can access, and produces an output that users can act on. For example, a support team might route incoming tickets by predicted urgency. A SaaS product might identify accounts with churn risk. An ecommerce platform might personalize product recommendations. A logistics team might predict late deliveries before customers ask for updates.
Score each candidate by value, data readiness, integration complexity, risk, and feedback availability. Feedback matters because the feature needs a way to learn from accepted, rejected, corrected, or ignored predictions. If users cannot close the loop, the system becomes hard to improve.
A practical discovery output is a one-page use-case brief. It should include the current workflow, user roles, systems touched, prediction target, decision threshold, success metric, expected value, constraints, and pilot scope. This also helps decide whether ML is the right path or whether AI workflow automation with retrieval, rules, and integrations is enough for the first release.
Audit Data Before Promising Accuracy
Data readiness is the most common blocker in machine learning integration. Existing apps often store useful signals, but not always in model-ready form. Events may be missing. Labels may be inconsistent. Fields may have changed meaning over time. Historical data may sit across a CRM, ERP, analytics warehouse, files, support tool, and custom database with different owners.
Run a data audit before promising a model accuracy target or production date. The audit should answer:
- Which systems contain the inputs needed for the first model?
- Which historical outcome will be used as ground truth?
- How complete, current, duplicated, biased, or noisy is the data?
- Can training data be recreated later from versioned sources?
- Which records are sensitive and need masking, retention rules, or access controls?
- Which data must be available in real time at prediction time?
- Who owns fixes when source data quality breaks?
The output is not only a spreadsheet. It should become a build plan for pipelines, transformations, feature definitions, data contracts, and quality checks. When the data work is bigger than expected, start with a thin baseline and a cleanup backlog instead of forcing a production model too early.
Choose The Model Approach That Fits The Workflow
Model choice should follow the use case. A forecast may need time-series methods, gradient boosted trees, or a hybrid of statistical and ML approaches. A recommendation engine may start with collaborative filtering, content-based ranking, or rules plus personalization signals. A support classifier may begin with supervised classification. A document workflow may combine OCR, embeddings, LLM extraction, and human review.
For an existing application, the simplest reliable model is often the best first release. A baseline model creates an objective comparison against rules, reports, or manual review. If the baseline cannot improve the target metric, a more complex model may not solve the business problem either.
Compare models by evaluation quality, latency, explainability, update frequency, infrastructure fit, cost, risk, and operational support. The machine learning consulting company checklist is useful when you need to pressure-test vendor or internal team claims around baseline modeling, MLOps, cost, and ROI.
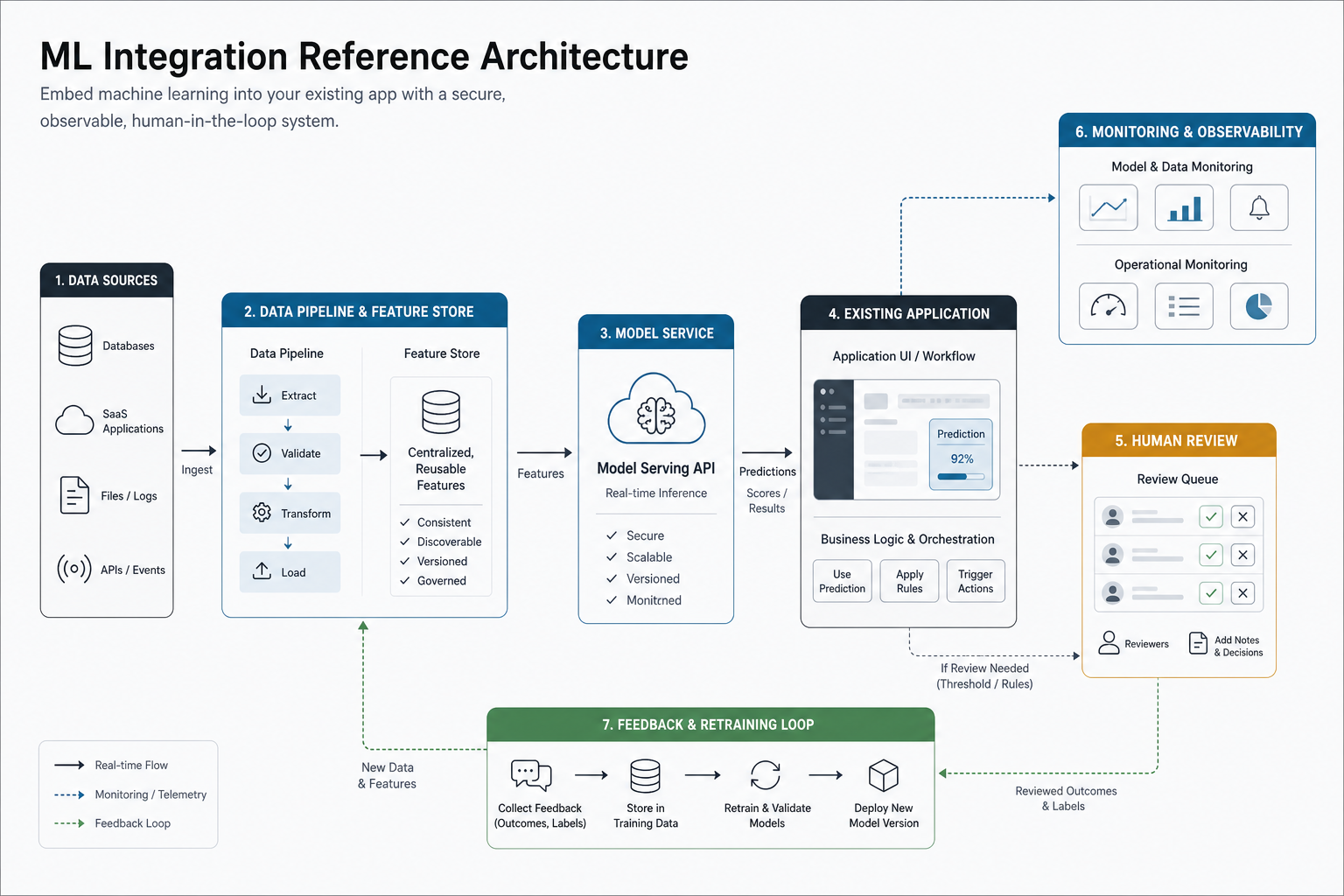
Reference Architecture For Integrating ML Into An Existing App
A production architecture has more than a model endpoint. It includes source systems, data pipelines, a reusable feature layer, a model service, application integration, user-facing UX, monitoring, logging, and a feedback loop.
A common pattern looks like this:
- Source systems: product database, CRM, ERP, analytics events, files, logs, or third-party APIs.
- Data pipeline: ingestion, validation, transformation, feature generation, and training dataset creation.
- Model service: versioned API or batch scoring job with authentication, request validation, rate limits, and observability.
- Application integration: existing screens, admin workflows, alerts, decision queues, reports, or background jobs consume the prediction.
- Human review: high-impact or uncertain outputs route to people for approval, rejection, correction, or escalation.
- Monitoring: track latency, errors, data drift, model quality, confidence bands, business KPIs, and usage behavior.
- Feedback loop: store outcomes and corrections so future model versions can be evaluated and improved.
This is why API and product integration work matters as much as data science. The ML service must fit the software architecture your users already rely on.
Design The User Experience Around Trust And Action
Users do not need to see every model detail, but they do need enough context to act responsibly. A risk score without explanation, confidence, next step, or override path is easy to ignore. A prediction inside the wrong screen can create more friction than value.
Design the ML output around the decision. For example, a churn-risk card might show the affected account, risk band, contributing signals, recommended retention action, and a way to mark the suggestion as useful or wrong. A recommendation module might show ranked products with merchandising rules and experiment tracking. A document classifier might show extracted fields, confidence, source evidence, and review status.
Good UX also defines fallback states. What happens when the model service is slow, unavailable, uncertain, or blocked by missing data? The answer should be built into the workflow before launch, not discovered during a support incident.
Build MLOps Before The Pilot Expands
MLOps is the operating system for production machine learning. At minimum, the team needs model versioning, reproducible training data, deployment gates, monitoring dashboards, alert thresholds, rollback, retraining triggers, and ownership for incidents.
For a pilot, keep MLOps proportional but real. You may not need a large platform on day one, but you do need to know which model version made each prediction, what data it received, whether input distributions are changing, how users responded, and who can pause or roll back the feature. The MLOps implementation checklist provides a deeper production checklist for deployment, monitoring, governance, and improvement.
Monitoring should combine technical and business signals. Track API latency, errors, missing features, drift indicators, confidence distribution, review rate, override rate, conversion impact, time saved, false positives, false negatives, and support tickets caused by the feature.
Keep the monitoring model practical: assign an owner, define alert thresholds, name rollback authority, and decide which signal triggers retraining, threshold adjustment, data cleanup, or a product UX change. Without those decisions, dashboards can show drift without giving the team permission to act.
Security, Privacy, And Governance Checks
ML integration often touches sensitive customer, operational, financial, health, or employee data. Treat security as part of the architecture, not a sign-off at the end.
- Define which data can be used for training, inference, logging, and debugging.
- Mask or minimize sensitive fields where the model does not need them.
- Use role-based access for datasets, model artifacts, logs, and review queues.
- Record model version, input references, output, confidence, user action, and override reason where auditability matters.
- Set retention rules for training data, inference logs, and user feedback.
- Document human review requirements for high-impact decisions.
- Plan a disable switch for model features that create operational or compliance risk.
If your workflow serves EU users or touches regulated decisions, pair the implementation plan with EU AI Act readiness for software teams or another risk-management review suited to your market.
The NIST AI Risk Management Framework is useful even when a workflow is not formally regulated because it separates governance work into govern, map, measure, and manage activities. For ML integration, that translates into ownership, context mapping, quality measurement, and an operating process for risks discovered after deployment.
Test The Feature Like Software And Like A Model
Machine learning integration needs two test layers. First, test the software: API contracts, permissions, latency, fallbacks, UI states, batch jobs, retries, logging, and deployment behavior. Second, test the model: offline performance, calibration, confidence thresholds, drift sensitivity, edge cases, bias risk, and business KPI impact.
Before production, define acceptance criteria for the pilot. Examples include prediction latency under an agreed threshold, review queue completion rate, precision or recall above a minimum level, measurable hours saved, better conversion, fewer escalations, or reduced manual triage time. Do not call the pilot successful only because the endpoint works.
Use staged exposure. Start with shadow mode when possible, where the model makes predictions but users do not act on them. Then move to decision support for a small group. Only after KPI evidence and user feedback are stable should the team automate actions or scale across departments.
Cost, Timeline, And Team Shape
The cost of ML integration depends on data readiness, source-system access, model complexity, UI changes, cloud usage, governance requirements, and post-launch support. A small decision-support pilot can be much lighter than a real-time recommendation platform or a regulated workflow with audit requirements.
| Workstream | Typical Responsibilities | Cost Driver |
|---|---|---|
| Product and discovery | Use-case framing, KPI model, pilot scope, stakeholder alignment | Number of workflows and decision owners |
| Data engineering | Source access, pipelines, transformations, feature definitions | Data quality, system count, historical coverage |
| ML engineering | Baseline model, evaluation, serving, monitoring, retraining plan | Model type, latency, explainability, feedback loop |
| Application engineering | API integration, UI changes, review queues, permissions, logs | Existing architecture and workflow complexity |
| Security and governance | Access control, audit logs, retention, risk review | Data sensitivity and compliance expectations |
| Operations | Monitoring, support, incident response, iteration | Usage volume and service-level expectations |
For early budget planning, use the Custom Software Cost Estimator to frame product complexity and the AI Automation ROI Calculator to test whether the workflow value justifies a pilot.
A Practical Phased Rollout Plan
A phased rollout reduces risk and gives the team time to learn. The goal is not to automate everything at once. The goal is to build confidence, collect feedback, and expand based on evidence.
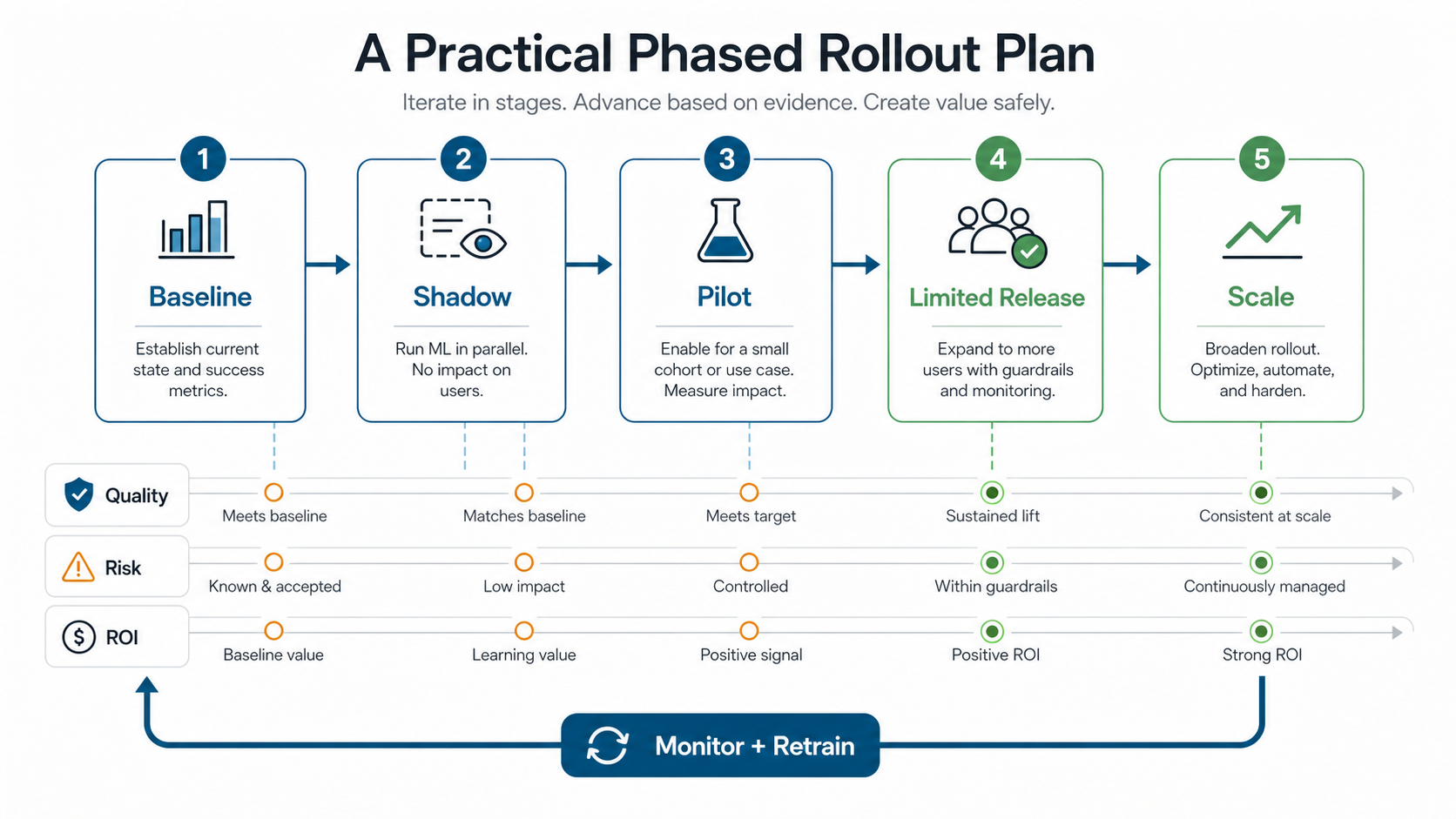
- Discovery sprint: confirm use case, data sources, integration points, risks, KPIs, and pilot boundaries.
- Data readiness sprint: connect source systems, profile data, define labels, and build repeatable datasets.
- Baseline sprint: train or configure a simple model, compare against current workflow, and decide whether to continue.
- Integrated pilot: expose predictions in the existing app for a limited group with review and feedback controls.
- Operational hardening: add monitoring, alerts, access controls, documentation, rollback, and support ownership.
- Expansion: extend to more users, use cases, source systems, or automated actions only after measured results are stable.
Common Mistakes That Delay ML Integration
- Starting with an algorithm before defining the workflow decision.
- Assuming data is clean because dashboards already exist.
- Building a model outside the application team that must integrate it later.
- Ignoring latency, fallback states, permissions, and operational support.
- Skipping human review for high-impact or uncertain predictions.
- Launching without model versioning, monitoring, or rollback.
- Measuring model metrics but not business outcomes.
- Expanding beyond the pilot before feedback and KPI evidence are stable.
A strong program treats each mistake as a gate, not a lesson learned after launch. If data ownership, monitoring, model rollback, or user trust is unclear, fix that operating gap before adding more use cases or automating more decisions.
How NextPage Helps With Machine Learning Integration
NextPage helps teams turn ML ideas into working product and operations features. We can assess use-case fit, audit data readiness, design the model service architecture, build API and application integrations, add human review workflows, set up monitoring, and plan the rollout path from baseline to production.
If you already have an app, CRM, ERP, dashboard, or internal workflow and want to add predictive features, start with a focused integration roadmap. Bring the target workflow, data sources, current process pain, expected metric, and existing architecture. We will help decide whether the right next step is data cleanup, a baseline model, an integrated pilot, or a production ML feature.