
A product recommendation engine can improve discovery, basket building, repeat purchases, and customer experience, but only when it is planned as an ecommerce product system. The engine needs clean catalog data, reliable user-event tracking, thoughtful placements, merchandising controls, experimentation, and monitoring. Without those foundations, recommendations become random product widgets that customers learn to ignore.
This roadmap is for ecommerce teams that want to move beyond static related products and plan a recommendation MVP that can grow into a reliable personalization layer across the website, mobile app, email, and support workflows. If the recommendation layer is already a board-level growth priority, NextPage's AI recommendation engine development services can help turn the roadmap into a scoped data, model, API, and rollout plan.
Quick Answer: What Does An Ecommerce Product Recommendation Engine Need?
An ecommerce product recommendation engine needs product catalog attributes, behavioral events, user or session context, recommendation logic, business rules, storefront placements, analytics, and a feedback loop. Start with a small number of high-value placements, such as product detail recommendations, cart add-ons, collection-page ranking, and post-purchase suggestions. Then measure click-through rate, add-to-cart rate, average order value, conversion rate, return rate, and margin impact before expanding.
The safest roadmap is not to build every algorithm first. Start with data quality and a clear commercial hypothesis, launch a controlled MVP, compare it against a baseline, and improve the system only when the measurements show where better personalization will matter.
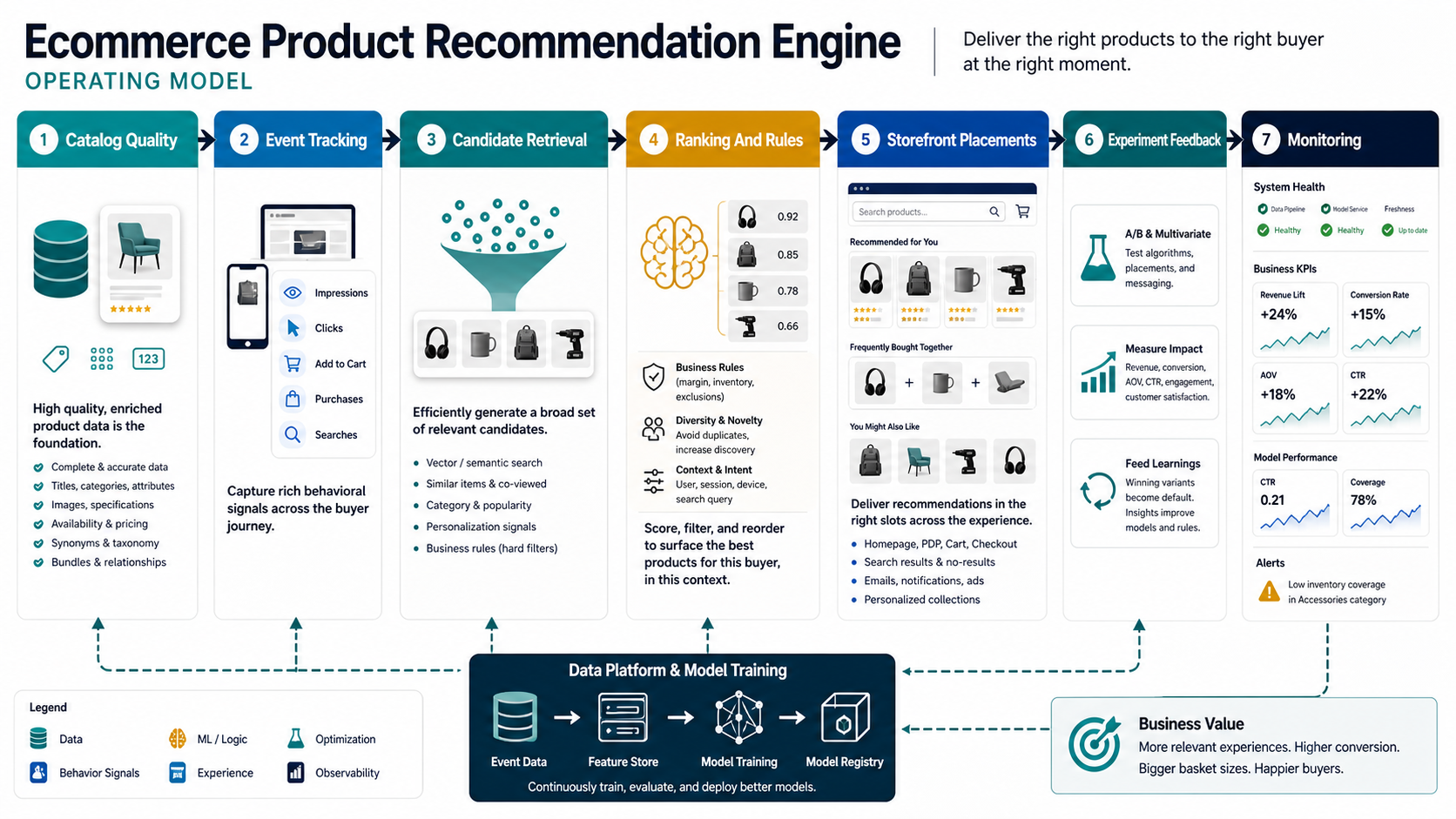
1. Define The Business Case Before Choosing Algorithms
Recommendation projects drift when the team starts with model choice instead of business outcome. Decide what the engine should improve first: product discovery, cross-sell, upsell, replenishment, bundle creation, onboarding, category navigation, personalized search, abandoned-cart recovery, or retention.
Each goal needs a different placement and metric. A product-detail widget may aim to increase add-to-cart rate. A cart recommendation may target average order value. A home-page personalization module may improve repeat engagement. A replenishment recommendation may improve customer lifetime value. If the metric is unclear, the team cannot tell whether the recommendation is useful or just visually interesting.
For early prioritization, compare the expected revenue lift and operating effort against other automation ideas. The AI automation ROI calculator can help frame whether a recommendation MVP deserves investment now or should wait behind higher-confidence operational automation, while the custom software cost estimator can turn early feature assumptions into a directional budget range.
2. Build The Data Foundation: Catalog, Events, And Context
Recommendation quality depends on the signals available. The catalog should contain structured attributes such as category, brand, price, margin, size, color, material, compatibility, inventory state, seasonality, discount status, rating, style, and fulfillment constraints. If attributes are inconsistent, the engine will struggle to understand product similarity or rules.
User-event tracking is the second foundation. Capture page views, product impressions, search terms, filter use, clicks, add-to-cart events, removes, wishlist actions, checkout starts, purchases, returns, reviews, and support signals where appropriate. For logged-out traffic, session behavior still matters. For logged-in customers, purchase history and preference signals can improve recommendations if privacy and consent are handled clearly.
| Data Area | Examples | Why It Matters |
|---|---|---|
| Catalog attributes | Category, brand, style, price, margin, inventory, compatibility | Supports similarity, filtering, and merchandising rules |
| Behavioral events | Views, clicks, search, add-to-cart, purchases, returns | Shows intent and product relationships from real customer behavior |
| User context | Location, device, loyalty tier, past orders, session source | Helps personalize without overfitting to one signal |
| Business constraints | Stock, margin, launch campaigns, excluded products, compliance rules | Keeps recommendations commercially and operationally safe |
If you are still planning the broader commerce platform, include recommendation data in the early architecture. The budget drivers in an ecommerce app development cost plan often include analytics, integrations, catalog modeling, and admin controls, not just storefront screens.
3. Add Privacy-Safe Personalization And Governance
Recommendation engines now need a privacy and governance layer as much as they need model logic. Browser privacy changes, consent expectations, and first-party data strategies make it risky to depend on opaque third-party signals or unmanaged customer profiles. Treat consent status, data purpose, retention, and explainability as product requirements before the MVP reaches production.
Build the first version around first-party catalog and behavior signals the business can justify: product views, add-to-cart events, purchases, returns, inventory, margin, loyalty status, and declared preferences. Avoid collecting sensitive attributes unless the use case clearly needs them, the customer has a transparent choice, and the data is protected by policy and access controls. The 2026 planning assumption should be privacy resilience rather than cookie dependence: Chrome continues to expose user choice around third-party cookies, Shopify merchants can manually influence product recommendations through Search & Discovery, and recommendation experiments still need consent-aware analytics rather than hidden cross-site profiling.
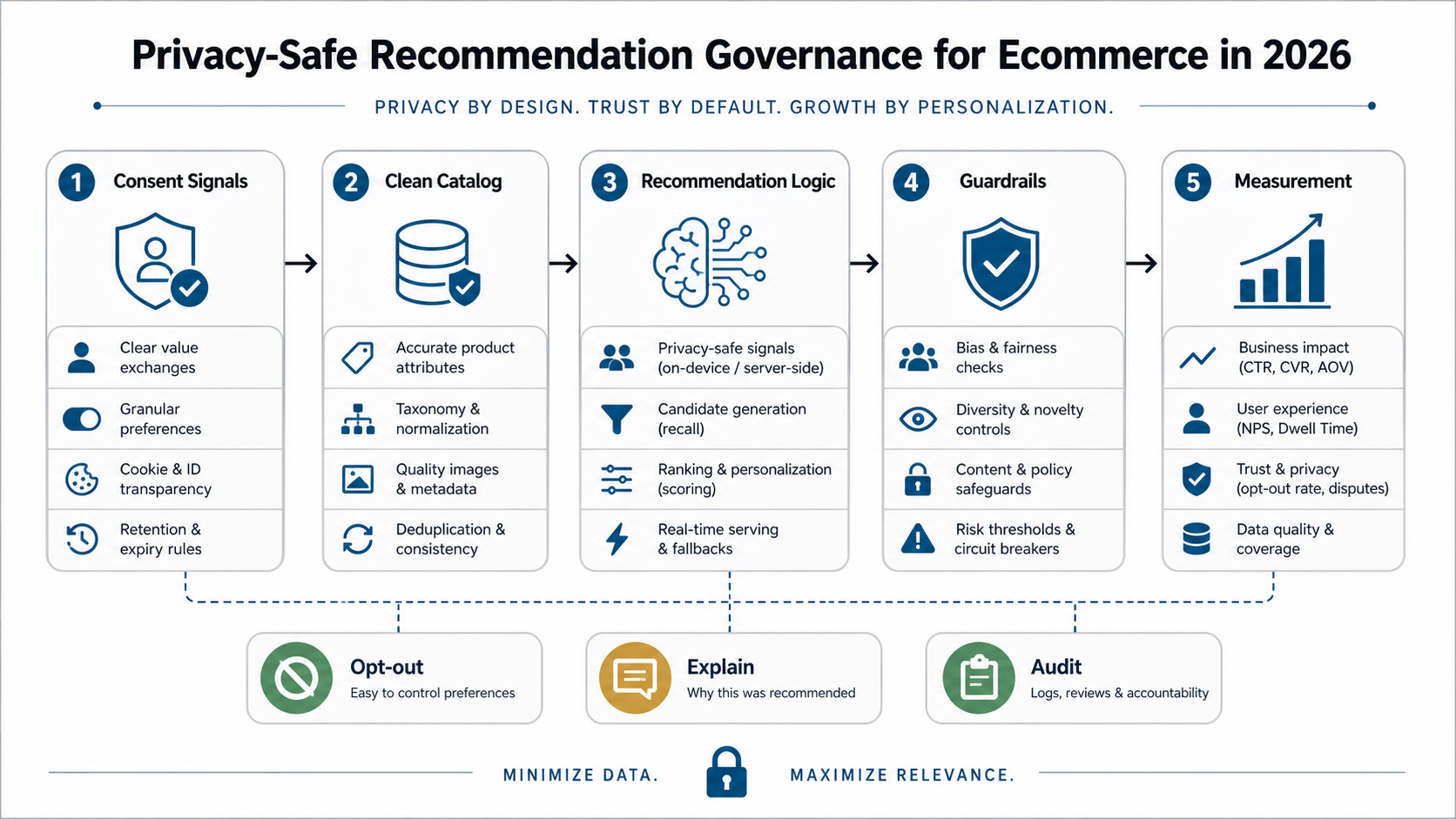
| Governance Layer | What To Decide | Why It Matters |
|---|---|---|
| Consent and preference signals | What can be personalized, what requires opt-in, and where customers can opt out | Prevents personalization from feeling hidden or invasive |
| Data minimization | Which catalog, event, purchase, and profile fields are actually required | Reduces privacy, security, and data-quality risk |
| Explainability | How merchandisers and support teams understand why products appeared | Makes poor recommendations easier to debug and improves customer trust |
| Audit and rollback | Who reviews rules, experiments, blocked items, and model changes | Keeps the engine operable after campaigns, seasons, or inventory change |
This governance work also affects build-versus-buy decisions. A packaged tool may be enough when consent, catalog, and placement needs are standard. A custom layer becomes more useful when the recommendation engine must coordinate customer permissions, marketplace rules, ERP inventory, pricing, loyalty, or brand-safety constraints across multiple channels.
4. Choose The First Recommendation Approach Conservatively
Most ecommerce teams do not need a complex deep-learning system on day one. Start with the simplest approach that can prove value with your available data.
Content-based recommendations use product attributes to suggest similar or complementary items. They work well when catalog metadata is strong and behavioral data is limited. Collaborative filtering learns from user and item interactions, such as customers who viewed or bought similar products. It can be powerful, but it needs enough traffic and transaction history. Rules-based recommendations use explicit merchandising logic, such as compatible accessories, in-stock alternatives, or margin-aware bundles. Hybrid systems combine these approaches.
A practical MVP might use content-based similarity for product detail pages, rules-based cross-sell in the cart, and simple popularity signals for new visitors. More advanced learning can come later when the team has enough clean interaction data and baseline experiments.
Build Vs Buy Decision: Packaged Tool, Hybrid Layer, Or Custom Engine?
Not every ecommerce team should build a full recommendation engine. The right path depends on differentiation, data maturity, control needs, integration complexity, and how quickly the team needs value. A packaged tool is usually best when the store has standard product-detail, cart, and collection-page recommendations. A hybrid layer fits teams that want vendor speed but need custom rules, inventory checks, margins, loyalty context, or marketplace logic around the vendor output. A custom engine makes sense only when recommendation quality is strategically differentiating and the business has enough clean event, catalog, and outcome data to operate it.
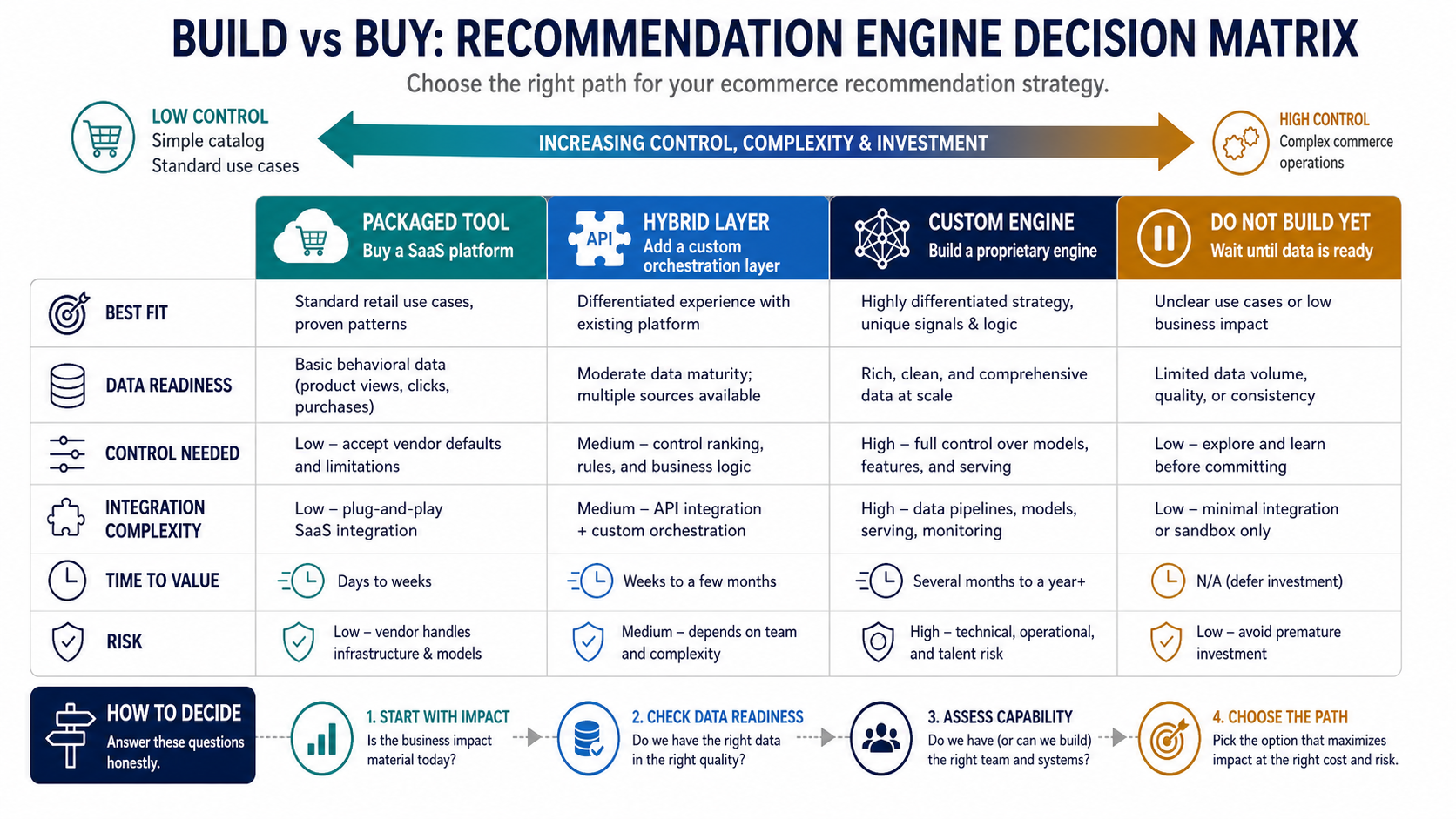
If the decision is still unclear, treat the first sprint as a readiness assessment. Confirm the use case, catalog quality, event instrumentation, traffic volume, integration constraints, and experiment design before committing to a platform contract or custom model roadmap.
5. Map Recommendation Placements Across The Shopping Journey
Recommendation engines create value through placements, not through model output alone. Map where customers need help making a decision and what kind of suggestion belongs there.
- Home page: personalize categories, trending products, recently viewed items, or seasonal collections.
- Search and category pages: reorder results, show compatible filters, or surface high-intent alternatives.
- Product detail pages: recommend similar products, accessories, bundles, size alternatives, or better-margin substitutes.
- Cart and checkout: suggest add-ons, replenishment items, warranties, or threshold-based bundles without distracting from payment.
- Post-purchase and email: recommend refills, compatible products, next-best categories, or reactivation offers.
Each placement should have a fallback. New products, anonymous visitors, out-of-stock items, limited categories, and low-traffic SKUs need safe defaults. Otherwise, the engine may hide useful products or show empty recommendation blocks.
6. Add Merchandising Rules Without Killing Personalization
Business teams need control over recommendation output. That does not mean every result should be manually curated. The right model is a guardrail layer: exclude out-of-stock products, respect brand restrictions, prioritize compatible items, avoid regulated or sensitive pairings, cap discount exposure, protect high-margin campaigns, and prevent repetitive recommendations.
Document which rules are hard constraints and which are soft preferences. A hard constraint might block a product that cannot ship to the shopper's region. A soft preference might gently boost new arrivals during a campaign. Mixing those two creates confusion for engineers, merchandisers, and analytics teams.
Custom business rules, ERP inventory, pricing logic, loyalty tiers, marketplace seller constraints, and campaign tools can materially change build effort. Use a custom software development cost lens when the recommendation engine must coordinate multiple systems instead of only reading storefront behavior.
7. Prove Value With A/B Tests And Operational Metrics
A recommendation engine should be measured against a baseline. Compare the MVP with existing static widgets, manual merchandising, or no recommendation block. Track click-through rate, add-to-cart rate, conversion rate, average order value, revenue per session, gross margin, return rate, recommendation coverage, latency, and customer complaints.
Be careful with vanity metrics. A widget can receive clicks because it is visually prominent but still reduce checkout completion. A recommendation can increase basket size while hurting margin or increasing returns. A useful experiment measures the full commercial outcome and watches for operational side effects.
Run experiments by placement and customer segment. New visitors, returning buyers, discount shoppers, high-value customers, and marketplace sellers may respond differently. Use those results to decide whether the next improvement should be better data, better model logic, better placement design, or better merchandising controls.
8. Plan The Integration Architecture
A recommendation engine usually touches more systems than expected. It may need product information management, CMS, ecommerce backend, inventory, pricing, search, mobile app, web storefront, email platform, CRM, customer data platform, analytics warehouse, and experimentation tools.
For each integration, define the data direction, update frequency, failure behavior, cache strategy, API ownership, privacy requirement, and rollback path. Product and inventory data may need batch syncs. Real-time recommendations may need low-latency APIs. Email recommendations may only need daily exports. Admin tools may need preview, pinning, exclusion, and campaign controls.
If the recommendation feature is part of a larger AI roadmap, work with an implementation team that can design around production constraints, not just model demos. NextPage's AI development services and machine learning development services focus on workflow fit, data sensitivity, evaluation, integration depth, operating cost, and production-grade model monitoring.
9. Monitor Quality After Launch
Recommendation engines need ongoing care. Monitor data freshness, event volume, product coverage, empty responses, latency, click behavior, conversion impact, inventory conflicts, blocked products, return patterns, and customer feedback. Also monitor whether recommendations become stale when campaigns, seasons, pricing, or inventory change.
Model operations can start simple, but someone must own it. Decide who reviews dashboards, who approves merchandising rules, who investigates poor recommendations, who updates evaluation sets, and who decides when a model or rule change is safe to release. The MLOps implementation checklist is useful once your recommendation engine moves from MVP to a maintained production system.
Recommendation Engine Readiness Scorecard
Before committing to advanced personalization, score the recommendation system against six launch gates: catalog quality, event coverage, placement scope, fallback behavior, merchandising controls, and experiment ownership. If any gate is weak, the next sprint should fix the foundation before adding more algorithms or placements.
| Readiness Area | Launch Standard | Owner |
|---|---|---|
| Catalog and inventory data | Core attributes are structured, current, and available to the recommendation service | Product ops and engineering |
| Event instrumentation | Views, impressions, clicks, add-to-cart, purchase, and return events are validated | Analytics and frontend engineering |
| Fallback logic | Anonymous users, sparse products, stockouts, and API failures show safe defaults | Backend engineering |
| Merchandising controls | Teams can pin, exclude, boost, and review rule impact without code changes | Merchandising and product |
| Experiment plan | Each placement has a baseline, success metric, guardrail metric, and review cadence | Growth and analytics |

A Practical 90-Day MVP Roadmap
A focused recommendation MVP can be planned in stages. The exact timeline depends on traffic, data quality, platform maturity, and integration complexity, but the sequence should stay disciplined.
| Phase | Focus | Output |
|---|---|---|
| Weeks 1-2 | Business case, placement selection, data audit | Recommendation brief, target metrics, data-gap list |
| Weeks 3-5 | Event tracking, catalog cleanup, rules design | Tracked events, structured attributes, merchandising guardrails |
| Weeks 6-8 | MVP recommendation logic and storefront integration | First model/rules service, product detail or cart placement |
| Weeks 9-10 | QA, fallback handling, analytics validation | Reliable recommendation blocks and experiment instrumentation |
| Weeks 11-12 | A/B test, review, next-scope decision | Measured lift, issue list, roadmap for expansion |
For ecommerce-adjacent examples, study how personalization and recommendations in food ordering apps depend on order history, location, timing, and promotion logic. The same lesson applies to retail: recommendations work best when they respect the buying context.
Common Mistakes To Avoid
- Launching recommendations before data is trustworthy. Poor product attributes and broken event tracking create poor recommendations.
- Measuring only clicks. Track conversion, basket value, margin, returns, and complaints alongside engagement.
- Ignoring business rules. Inventory, compatibility, compliance, and merchandising constraints need to be part of the system.
- Adding too many placements at once. Start where customer intent and measurement are strongest.
- Leaving ownership unclear. Recommendation quality needs product, merchandising, analytics, and engineering ownership after launch.
How NextPage Helps Plan Ecommerce Recommendation Engines
NextPage can help you turn a personalization idea into a buildable recommendation roadmap: data audit, event tracking plan, catalog model, MVP scope, recommendation logic, storefront integration, experimentation design, and production monitoring.
If you are planning a recommendation engine for a D2C store, marketplace, food ordering app, retail platform, or B2B ecommerce workflow, start with the smallest placement that can prove value. From there, the roadmap can expand into search ranking, email personalization, inventory-aware merchandising, and cross-channel customer journeys.